新手学电脑,请多多指教。
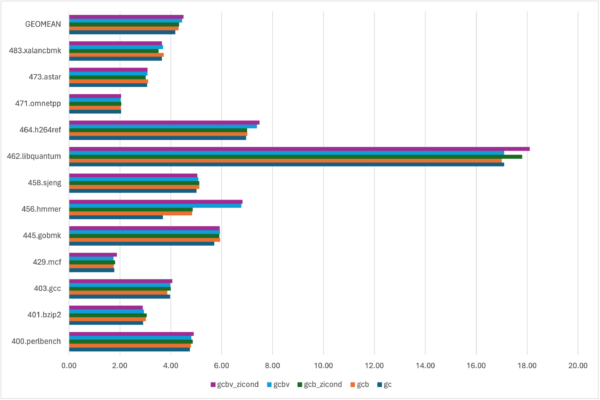
Spacemit X60 (K1) SPECINT 2006 Benchmark
I ordered a BananaPi F3 last week and it arrived on May 6th. Using the opensbi and kernel…
T-HEAD C910 SPEC CPU Benchmark
Enviroment Board: Lichee Module 4A (2GHz Version) SBI: revyos/opensbi/th1520-v1.3.1 Kernel: revyos/th1520-linux-kernel/th1520-master-wip SBI and Kernel Compiled with riscv64-linux-gnu-gcc version…
让树莓派4 WireGuard 性能从 400Mbps 飞涨到 1Gbps
背景 由于学校机房依然需要网络认证,因此我采用了使用 WireGuard 从别处接入网络的方式。为了评估放在学校机房的软路由需要什么样的性能才足够跑满千兆大包 WireGuard ,上周末写了个 WireGuard Benchmark 脚本 来评估 CPU 以及 Kernel 网络栈处理 WireGuard 的性能。为了方便评估以取得更多的结果,我采用 network namspace…
从与 AMBA AXI 的对比学习 TileLink
Background 最近仔细学习了一下 TileLink 以及 TL-C 的一致性协议,希望写一篇文章给 有AMBA AXI基础 的读者提供一篇 TileLink 快速入门的介绍。 本文参考的 TileLink Spec 基于https://starfivetech.com/uploads/tilelink_spec_1.8.1.pdf Variant Protocol Narrow…
Intel Data Dependent Prefetcher 对 SPEC CPU 2017 的影响
背景 最近在做一些商业硬件的 Data Dependent Prefetcher 测量,无意中注意到 Intel 13 代酷睿是有 Data Dependent Prefetcher 的,因此先进行了一个简单的尝试。 介绍与开关控制 介绍可以参考 Intel的文档 。 而根据…
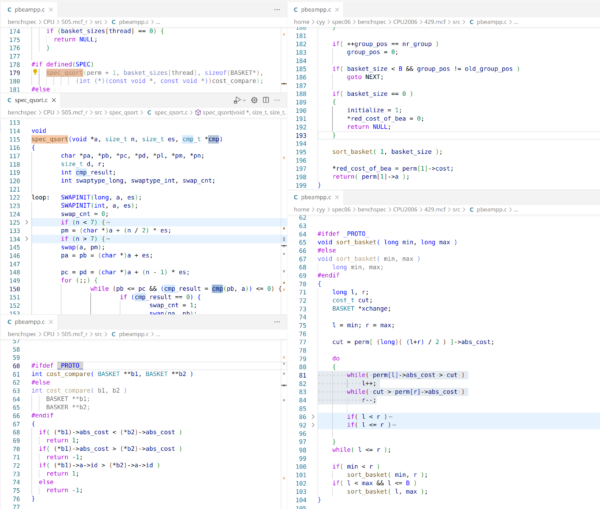
SPEC CPU 2017 mcf 与 2006 的差异浅析
背景 最近朋友 Easton Man 告诉了我一些SPEC CPU 2006 与 2017 的一些性能计数器 Topdown 统计结果,在观测他的结果后我惊讶地发现,SPEC CPU 2017中 mcf 这一 workload 对…
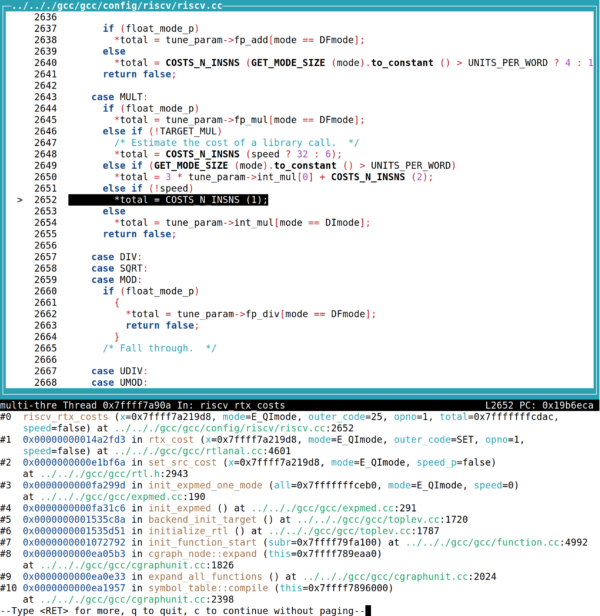
从CPU RTL到GCC expmed Cost Model
背景 最近和朋友讨论一个编码算法的问题的时候意外发现,当前 RISC-V 的 GCC 即使使用-O3优化的情况下,也不会将 divide by const 优化为Barrett reduction。但我测试了默认参数的 x86 、 aarch64 、 mips32 ,均存在该优化。且通常来说, CPU…

自己家的全屋光纤与无线覆盖布网实战
原则与实战结果 自己家今年搬入了新居,对于我来说一件十分重要的事情就是规划网络布线了。 我计划按照以下原则布置网络: 每个房间都有 4 芯光纤,确保以太网使用 2 芯之后还有 2 芯可用,从而可以接 HDMI 光端机等设备以及出现断芯等情况后可以替换。 有人活动的位置 5GHz WiFi RSSI <= -65…
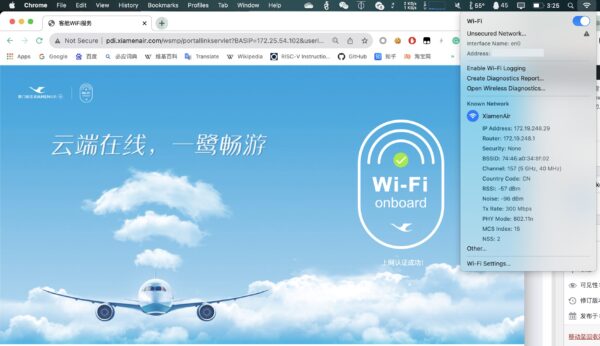
第一次在国内航班体验机上WiFi
于 2023 年 8 月 3 日乘坐了厦门航空的 MF8208 从西安飞往厦门,执飞飞机是一架 BOEING 787-8 宽体型客机,上飞机后惊奇地发现座位旁有 WiFi 图标,而在地面上我拿手机搜索了一圈并没有看到任何非个人热点的 SSID 。但我依然非常期待,因为距离上一次在空中上网已经是2014年在美国使用 gogoinflight 了。…
Back to Top