背景 自从香山新后端合并后, Chisel 编译时间大幅增加,特别是在双核的 DefaultConfig 下,在我的 13900K 机器 + OpenJDK 11 的条件下, FIR 的生成时间已经达到的 34 分钟,具体可以见该 issue ,而在之前,…
Chisel
Back to Top
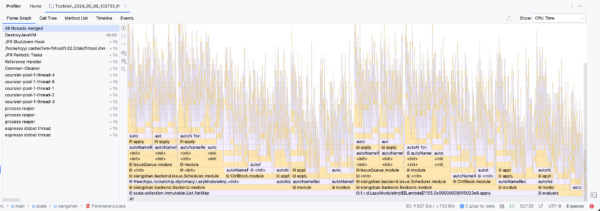
背景 自从香山新后端合并后, Chisel 编译时间大幅增加,特别是在双核的 DefaultConfig 下,在我的 13900K 机器 + OpenJDK 11 的条件下, FIR 的生成时间已经达到的 34 分钟,具体可以见该 issue ,而在之前,…