浅谈早期 Fault Tolerance 虚拟机原理
背景
最近遇到了一些灵车硬件损坏问题,包括自己的台式机 13900K CPU 突然死机后重启就出现 CPU soft lockup,再重启直接无法点亮;自己的旧台式机出现 Correctable ECC 报错(感谢AMD消费级CPU也部分支持ECC);以及一台别人的服务器上解压tar.gz包出现了CRC错误。一周内的这些经历使我开始思考云计算场景如何Tolerance这些奇怪的硬件损坏问题,于是看到了一篇VMWare vSphere 4(2010)年代的论文——The Design of a Practical System for Fault-Tolerant Virtual Machines。
什么是 Fault Tolerance
这里我们的 Fault Tolerance 特指 VMWare 的 Fault Tolerance ,它确保一个虚拟机在两个物理 Host 上有两份副本,并在另一台虚拟机Ack本次同步的消息之前延迟 IO 的发送,从而不会出现网络数据包的状态不一致,进而可以确保即使其中一个物理 Host 在没有任何征兆的情况下 Down ,也可以由另一台物理 Host 继续接管该虚拟机的执行。
Fault Tolerance 不同于 Live Migration (vMotion) 以及 VMWare 的 High Availability ,Live Migration 的实现需要保证当前执行的 Host 可用,而 Fault Tolerance 不需要,这也给 Fault Tolerance 带来了更多的限制(例如虚拟机的CPU核心数)以及性能开销。
评估结果
我们先来看一下这篇文章里提到的评估结果:
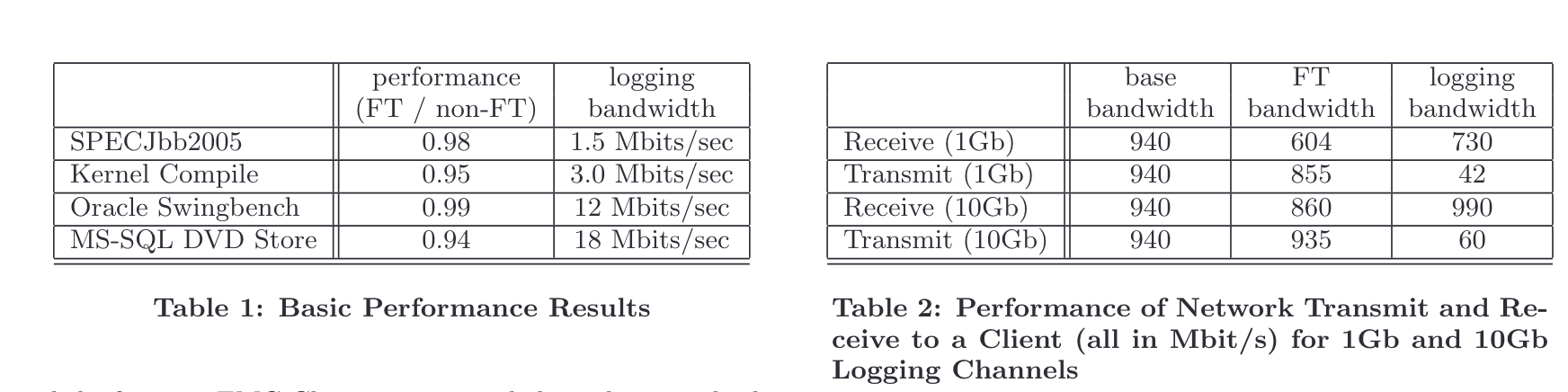
可以直观看出,这些 Workload 在运行时仅需要几十 Mbps 级别的 logging ,我起初非常疑惑,因为我一直在想多核场景下如何解决多个 Guest 的 vCPU Record and Replay问题。如果假设这么点带宽是 Practical 的,那么他们又是怎么同步内存状态的呢?
因为在 SMP 场景中,因为共享内存的存在,不同的CPU在执行时不可能做到完全同步,这个时候要实现 Record & Replay 需要维护的元数据相当多,如果要求低带宽不去维护内存状态的转移则不容易在软件层面解决(理论上可以实现基于虚拟化页表的缓存一致性协议,但是性能开销非常巨大),许多 Memory Consistency 的验证工作都是基于访存已经提交到总线全局可见的顺序来做的。
方法
后来,我仔细阅读了论文,发现他们开头就介绍了他们的方法是基于 deterministic replay ,而对于SMP场景,他们的方法就是不考虑。
VMware Sphere Fault Tolerance (FT) is based on deterministic replay, but adds in the necessary extra protocols and functionality to build a complete fault-tolerant system. In addition to providing hardware fault tolerance, our system automatically restores redundancy after a failure by starting a new backup virtual machine on any available server in the local cluster. At this time, the production versions of both deterministic replay and VMware FT support only uni-processor VMs. Recording and replaying the execution of a multi-processor VM is still work in progress, with significant performance issues because nearly every access to shared memory can be a non-deterministic operation.
如果不考虑 SMP 场景,只有单核,那方法就非常显然了。我们只需要通过 PMU 的溢出中断事件实现执行了指定数量的指令后精确的时钟中断,以及模拟外设以及 CPU 的性能计数器完全一致的访问行为即可,这些对于 Hypervisor 而言都非常简单,大家可以自行阅读论文学习。由于这样的方法不需要实时同步共享内存,仅需要同步外设操作、时钟中断、高性能计数器的访问,因此显然仅需要很小的带宽就可以实现。在2010年那个时代,许多应用并不能很好地利用多个CPU核心,在非常低的网络带宽要求下只实现单核还是非常有意义的。
最终,VMware 在 VMware vSphere™ 4 Fault Tolerance: Architecture and Performance White Paper 中用一张图诠释了整个架构:

现在
自2016年的vSphere 6.5起, Fault Tolerance 功能有了一个巨大的更新,那就是整体的架构不再基于deterministic replay,用了类似 vMotion 迁移的方法,也正是因为这样的方法考虑了内存状态的迁移,因此能够扩展到 SMP 场景,同时也不再要求 secondary node 需要有 primary node 相近的 CPU ,毕竟只同步状态,不再需要及时重放+ ack 。
由于具体的资料不多,我最终只找到一个对 vSphere 7 的介绍视频——31. What is vSphere Fault Tolerance (FT)? | FT Architecture | Fast Checkpointing | How does FT Work?
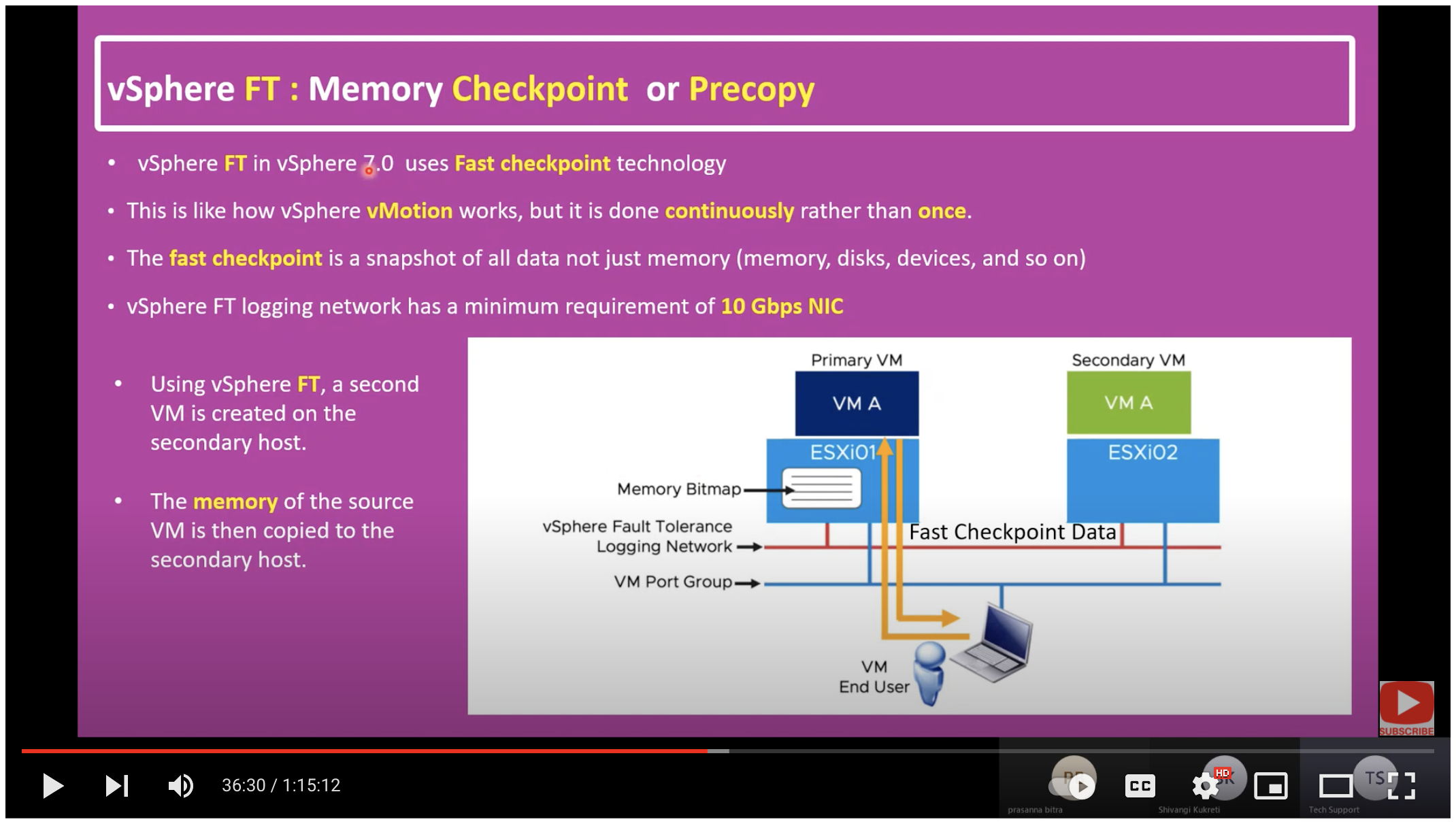
我想这张图已经诠释了一切。这也是为什么到了 vSphere 6.5 后将 Fault Tolerance 功能的带宽要求从 1Gbps 变成了 10Gbps 。
云计算场景真的需要 Fault Tolerance吗?
当然不是, Live Migration 已经足以满足云计算场景SLA的基本需要,比如内存损坏前通常会先产生大量的Correctable ECC错误,此时就可以先将虚拟机迁移到其它Host,再更换硬件,而不必使用可靠性非常高的 Fault Tolerance 架构。
讨论
至此,相信大家和我一样十分关注一个问题,那就是 vSphere 6.5 之后的 Fault Tolerance 架构面对 spatial locality 不好的大带宽 memory write 场景的性能表现,我还没找到相关资料,如果大家也有兴趣也有平台欢迎进行相关测试后和我讨论。