新手学电脑,请多多指教。
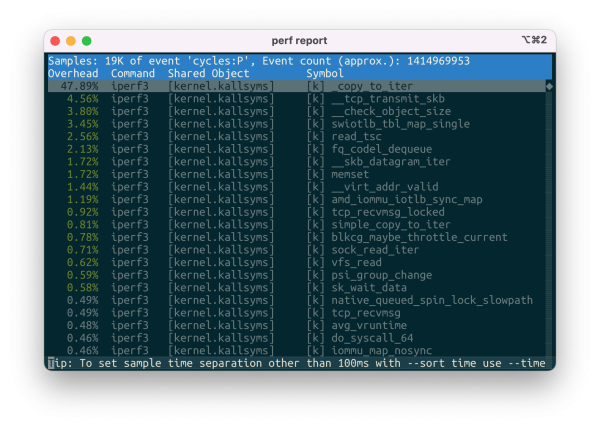
惊人的 IOMMU Overhead 与不合理的 AQC 网卡驱动
背景 给家里的 AMD AI MAX 395 小主机加了个 Thunderbolt 万兆网卡,期望给这台小主机通上 10Gbps 的信息高速公路,这样我可以利用家里的 NAS 的大容量存储快速拉 LLM ,网卡用的是几年前买给 Mac 用的 QNAP…
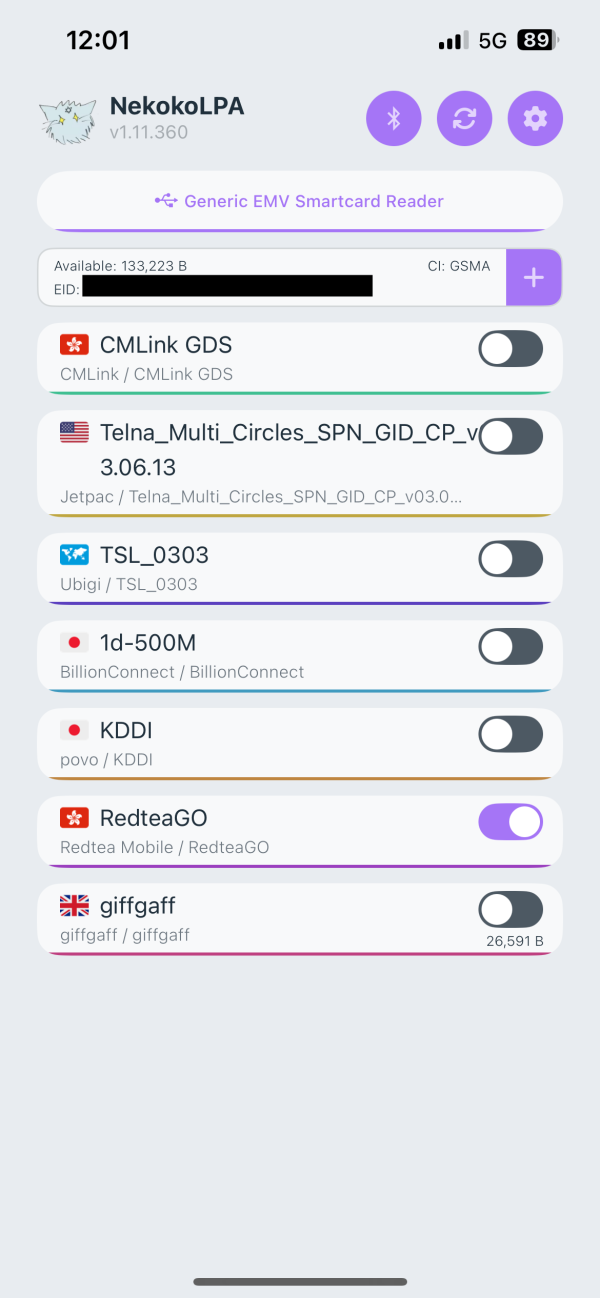
非原生 eSIM 手机出国旅游 eSIM 使用指北
背景 最近两个月去了法国和日本开会,发现 eSIM 在旅游时使用非常方便,我们可以直接在网上购买旅行 SIM 卡套餐然后扫码下载,主要好处包括: 套餐自由选择,可以按照自己最低需求购买低价套餐,不必担心部分 SIM 卡无法流量充值的问题,不够用就随时再买一张 低可用性风险,遇到问题随时可以下载新的 SIM 卡使用,不必等待快递或是出门找商店 灵活切换运营商,遇到某个运营商信号不好,此时有其他运营商 eSIM 时,可以在手机上点击菜单直接完成切换,而无需带着取卡针更换实体 SIM 卡 (比如我们去…

RISC-V Summit Europe 2025 游记
前言 最近参加了 RISC-V Summit Europe 2025 ,在各种体验上是最近几次开会体验感最好的一次,决定更新一下游记。 行前准备 日用品 去欧洲国家要特别注意酒店一般不提供牙膏、牙刷、拖鞋,因此要备上,因为一个月前 ASPLOS 去过荷兰所以也有经验了。之前乘坐南方航空去荷兰在飞机上还发了个装有牙膏和牙刷的小袋子。然而这次坐国航并没有这样的东西,为上次南方航空点赞! 转换插头 正常欧标 支付 几乎所有 PoS 机支持非接触的…
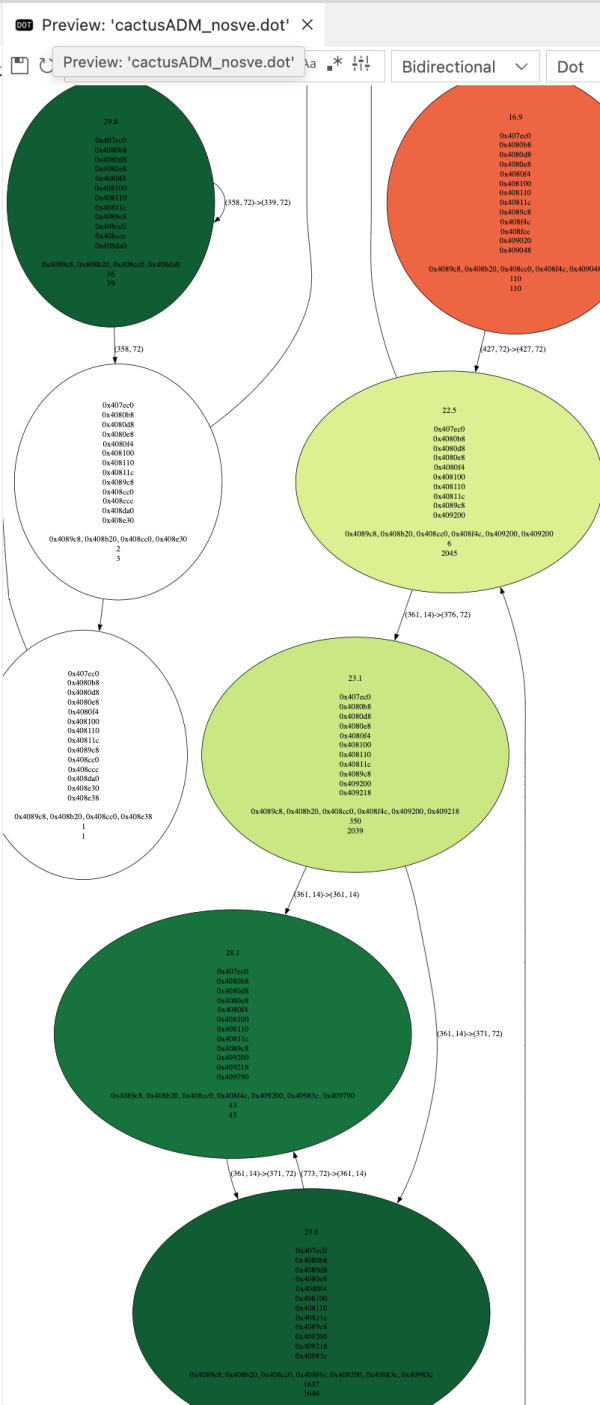
Can we trust the cpu cycles from LLVM-MCA?
Background Recently, I’ve been delving into the ARM SVE2 speed-up over pure NEON in common workloads that are…
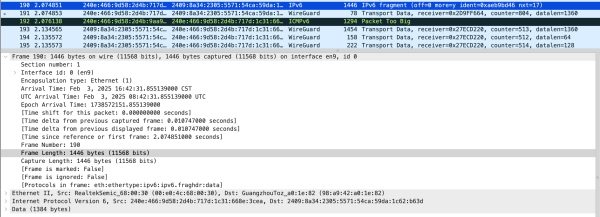
网络设备(特指 TP-Link)距离正确处理 IPv6 Fragmentation 还有多远
背景 过年在外婆家住了几天,因为这里没有装宽带于是带上了 5G CPE ,以及随便购买了 TP-Link 7DR3630 路由器(现已退货换其他产品) ,为几天后外婆家安装宽带做好准备。由于我的大部分工作数据放在家里的服务器上,出于习惯一般喜欢连接 WireGuard VPN 回家。而连接公共 WiFi 时我一般习惯加上默认路由到 VPN ,结果今天回到外婆家里连着 5G CPE…
How CCMP reduce the pressure of branch predictor on aarch64
Preface When comparing branch MPKI (Miss Per Kilo Instructions) on aarch64 with other architectures such as RISC-V (including…
“Short-leg” of RISC-V | RISC-V 的小短腿
Preface I came across some code performance issues only on RISC-V recently. Their root cause is the short…
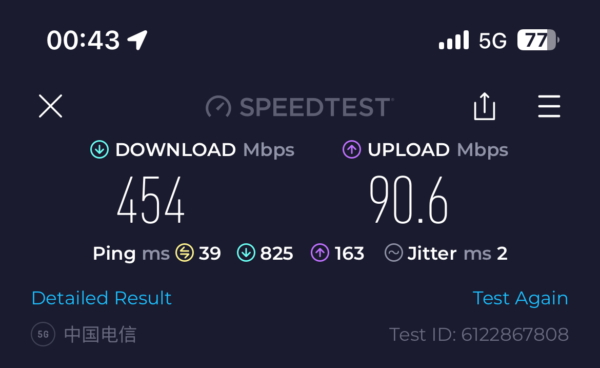
在 5G NR 时代,我们真的该大规模部署 TCP BBR 了
背景 自从 Speedtest.net 在 2 年前增加了下载与上传时的 ping 测试后,我们往往会在 LTE / 5G 上观测到其下载和上传占满空口带宽后出现了延迟大幅飙升的情况,而这一情况在使用 WiFi 时影响非常小,但在使用基于 10G EPON / XGPON的有线ISP(有限速)中几乎不存在。这就导致我们使用…
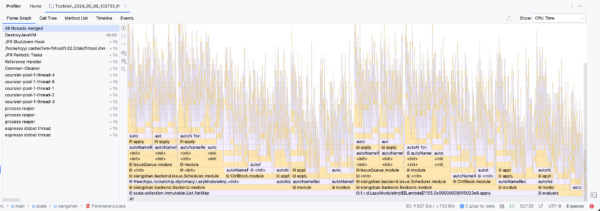
Chisel编译时间优化实例——将香山的双核RTL生成时间从36分钟压缩到7分钟
背景 自从香山新后端合并后, Chisel 编译时间大幅增加,特别是在双核的 DefaultConfig 下,在我的 13900K 机器 + OpenJDK 11 的条件下, FIR 的生成时间已经达到的 34 分钟,具体可以见该 issue ,而在之前,…
Back to Top