DDR4与HBM在UltraScale+ HBM上的IOPS测试
最近一个科研 idea 需要 measure 一些内存器件的 latency 数据,因此用 FPGA 对主流的内存器件的访问 Latency 进行了一个调研,诚然这样的结果和 FPGA 上具体 Memory Controller 的 IP 实现有关,但也可以作为一个参考,相信 Xilinx 的实现。
实验基于浪潮 F37X FPGA 卡, FPGA 采用与 VCU128 相同的 vu37p ,属于 Xilinx Ultrascale+ HBM 系列,具体型号也与 VCU128 完全相同,这个卡其实设计和 U280 非常类似,但是比 U280 多了一个通道的 DDR4 也多了 8GB 存储容量,个人觉得还是一个比较不错的卡(但可惜不好买,我在闲鱼上买还遇到了奸商,买两张确认收货后发现有一张卡综合后的bit流如果有逻辑分布在指定 bank 就会有问题,结果卖家不懂 FPGA 也不认,巨大亏损)。
vu37p 本身有 2 个 4GB 的 HBM , Xilinx 官方介绍其拥有 460GB/s 的 bandwidth ,我使用的这张 FPGA 卡也拥有 3 通道的 72bit DDR4 2400 8GB 内存(额外 8bit 用于 ECC ),一共 24GB 容量。
测试代码
为了做这个测试,我自己写了一个名为 axi_iops 的小项目,位于github.com:cyyself/axi_iops.git ,纯Verilog大概200行,用于对AXI随机读性能进行测试。该测试会使用LFSR随机生成一个地址,然后按照用户给定的arlen,arsize去发送请求。
在这个代码中,我们重点关注以下几个IO:
module axi_iops #(
parameter LFSR_INIT = 0,
parameter ADDR_LEN = 32,
parameter DATA_LEN = 64,
parameter ID_LEN = 6,
parameter LEN_SIZE = 4 // 4 for AXI3, 8 for AXI4, Xilinx HBM IP only provides AXI3 interface
) (
input clock,
input reset,
output [ID_LEN-1:0] axi_awid,
// 省略其他AXI信号
output axi_rready,
output [31:0] iocount_period,
input [2:0] debug_arsize,
input [LEN_SIZE-1:0] debug_arlen,
input debug_pause
);当每次收到rvalid&rast时,计数器会+1,每当过了2**32次时钟上升沿后,计数器的值会出现在iocount_period上,然后将计数器自身清零,相关代码是这么写的:
reg [31:0] timestamp;
reg [31:0] io_count;
reg [31:0] io_count_out;
assign iocount_period = io_count_out;
always @(posedge clock) begin : counting
if (reset) begin
timestamp <= 0;
io_count <= 0;
io_count_out <= 0;
end
else begin
timestamp <= timestamp + 1;
if (timestamp == 0) begin
io_count_out <= io_count;
io_count <= 0;
end
if (axi_rvalid && axi_rlast) begin
io_count <= timestamp == 0 ? 1 : (io_count + 1);
end
end
endDDR4环境
DDR4这个大家会看这篇文章的应该都比较熟悉,我的开发板配置采用的是2400 CL16 72bit ECC,如图:

此时AXI时钟使用4:1分频,2400/2/4=300MHz。由于AXI此时数据位宽为512,因此我们得到AXI接口可用的总带宽=300*512/8/1000=19.2GB/s。
HBM环境
这是本人第一次玩HBM内存,首先先介绍一下Xilinx IP的配置:

首先我们可以设置我们要使用多少片HBM,我这里只选择一片一次HBM Density就是4GB,因为目标是测IO速率与Latency情况下,尽量排除干扰。当选择HBM Desnity为8GB,如果开启一个Enable Switch/Global Addressing选项就可以在每一个AXI接口访问整体的8G内存。(在这种情况下,从一个Stack的AXI Slave接口访问另一个Stack会增加延迟,无论AXI频率多少,我通过AXI JTAG+ILA验证了这个问题。)
然后,根据Xilinx手册 AXI High Bandwidth Memory Controller LogiCORE IP Product Guide (PG276) 可知,AXI接口的极限速率是450MHz(虽然我未曾跑出一个450MHz WNS为正的结果,即使我只接了几个AXI转换器再接上一个AXI JTAG),AXI接口的数据位宽为256bits,而对于宣称的460GB/s带宽,每个Stack提供了16个AXI接口,如果使用两片HBM达成8GB容量就有2个Stack,450MHz的AXI频率下,采用256 bits的数据位宽,最终总速率=450*256*16*2/8/1000=460.800GB/s。但由于我的能力所限,最终只能让AXI在300MHz下工作,所以理论性能直接比标称砍了1/3。
DDR4
单请求访问延迟
在这个测试中,我首先通过一个AXI JTAG发访存请求,然后通过System ILA观察arvalid到rvalid时间。

可以看到,512个cycle时的arvalid,后续在第533个cycle时得到第一个rvalid,延迟大约21个cycle,多次测试结果也是大概如此,由于300MHz下一个cycle为3.33ns,最终得到内存延迟为70ns。
1字节随机访问
这里我首先进行了完全随机的随机访问测试,即通过AXI接口发送arsize=0,arlen=0的请求,这样每次请求只有一个字节,观测一段时间内的IOPS数量,在这个测试中,我设置arid长度为10位,这样极端情况下可以有1024个请求交错。
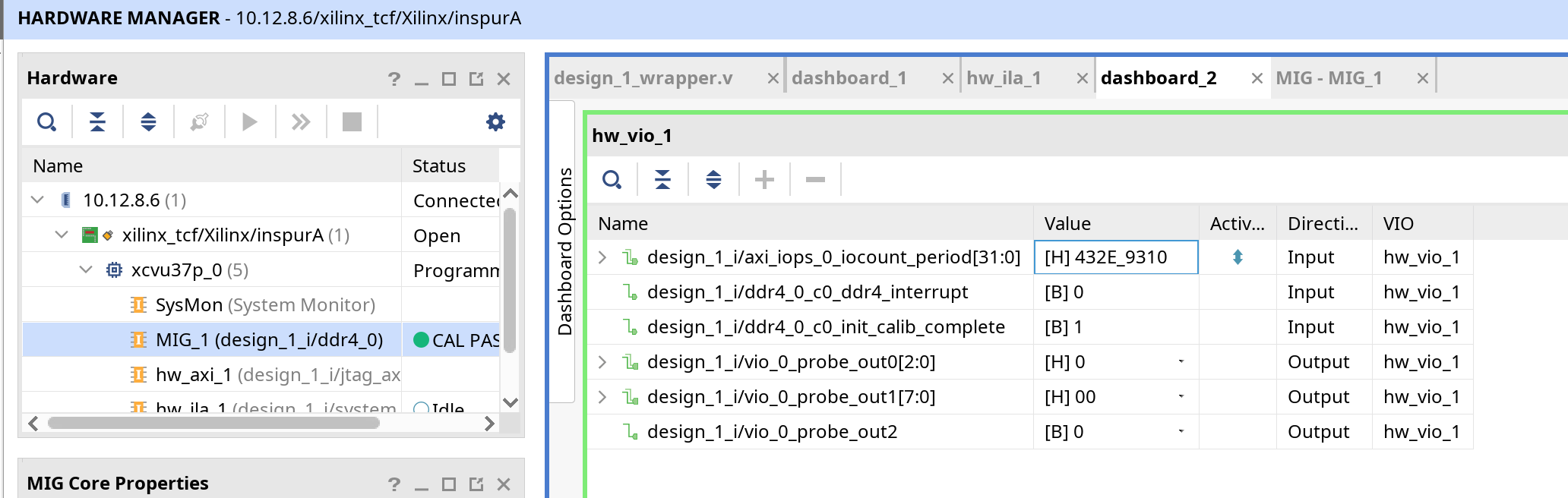
由于我的模块接入300MHz时钟,计数器每个时钟上升沿加1,同时计数器共32位,因此每次输出计数器结果为2**32/(300*1000*1000)=14.317s的结果,我们最终计算得到IOPS为 0x432e9310/(2**32/(300*1000*1000))/1000/1000=78.72882597148418,大约79M IOPS。但显然,我们如果不通过arid每次给多个地址请求,无法达成这个数量。说明Xilinx MIG对于多地址请求同时发出具有良好的支持。
最大Burst访问

我们得到总吞吐量为0x2ecf8d5*64*512/8/(2**32/(300*1000*1000))/1000/1000/1000=14.04GB/s,达到了理论带宽的约3/4。
HBM
单请求访问延迟
在这个测试中,为了测试多Stack的场景,我对先前所述的配置进行了微调,具体而言,每个Stack只留下一个AXI Slave接口,连接通过protocol converter和dwidth converter连接AXI JTAG,并允许每个AXI Slave接口访问两个Stack一共8GB的地址空间,最终得到延迟如下:
访问Stack自身的HBM MC:

由558-512=46得46个cycle,换算延迟为46*(1000/300)=153.33ns,比DDR4 2400 CL16高了一倍还多。
访问另一个Stack的MC:

由576-512=64得64个cycle,换算延迟为64*(1000/300)=213.33ns,已经是DDR4 2400 CL16延迟的3倍了(Xilinx你说好只多6个Cycle的呢?)。且我尝试调整arlen大小延迟没有发生误差外的改变。
1字节随机访问
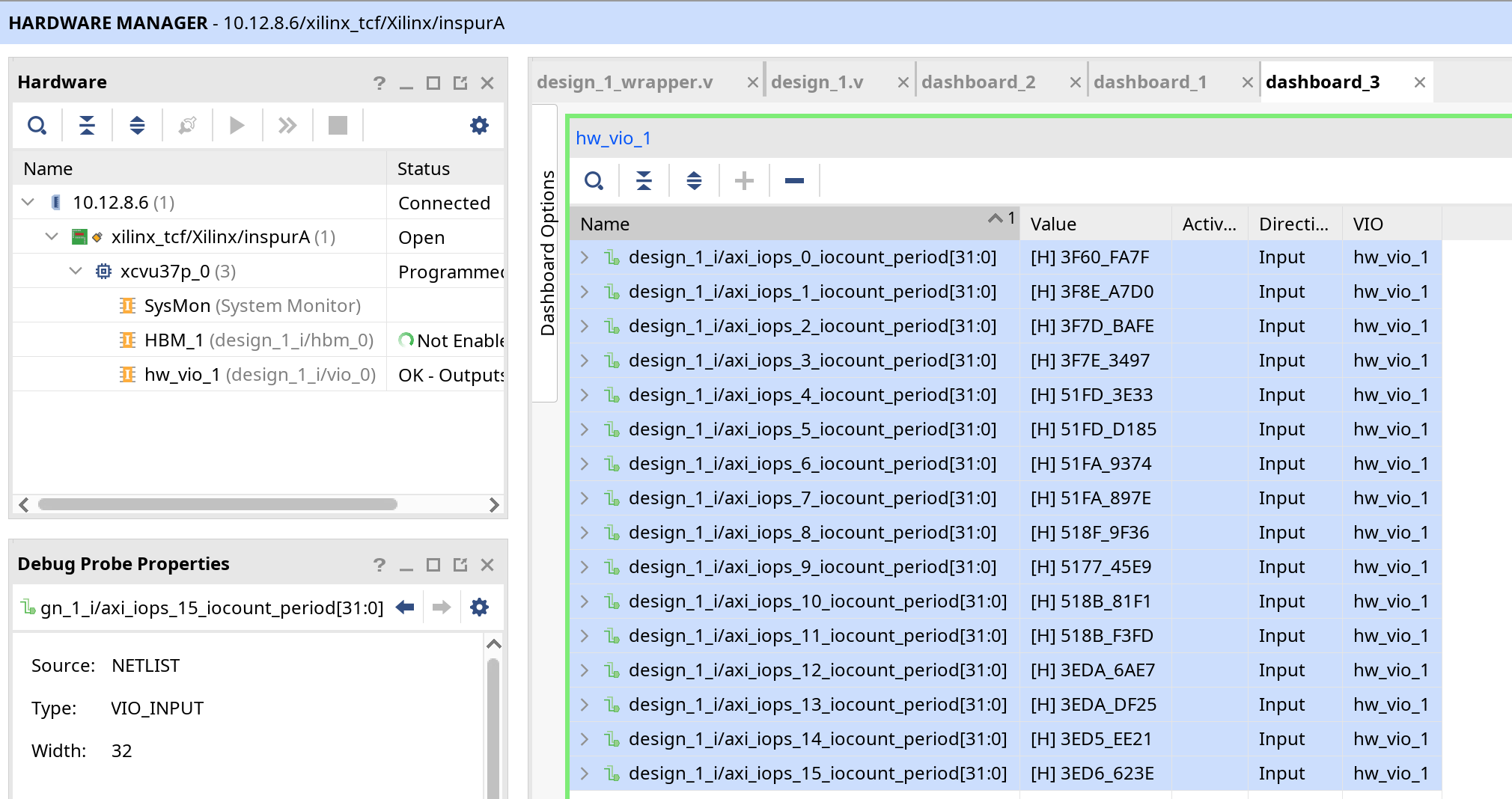
我们对这些数字求和,得到0x4875bb406,IOPS为 0x4875bb406/(2**32/(300*1000*1000))/1000/1000=1358.622909011319,达到了惊人的1358.62290 MIOPS。
最大Burst访问
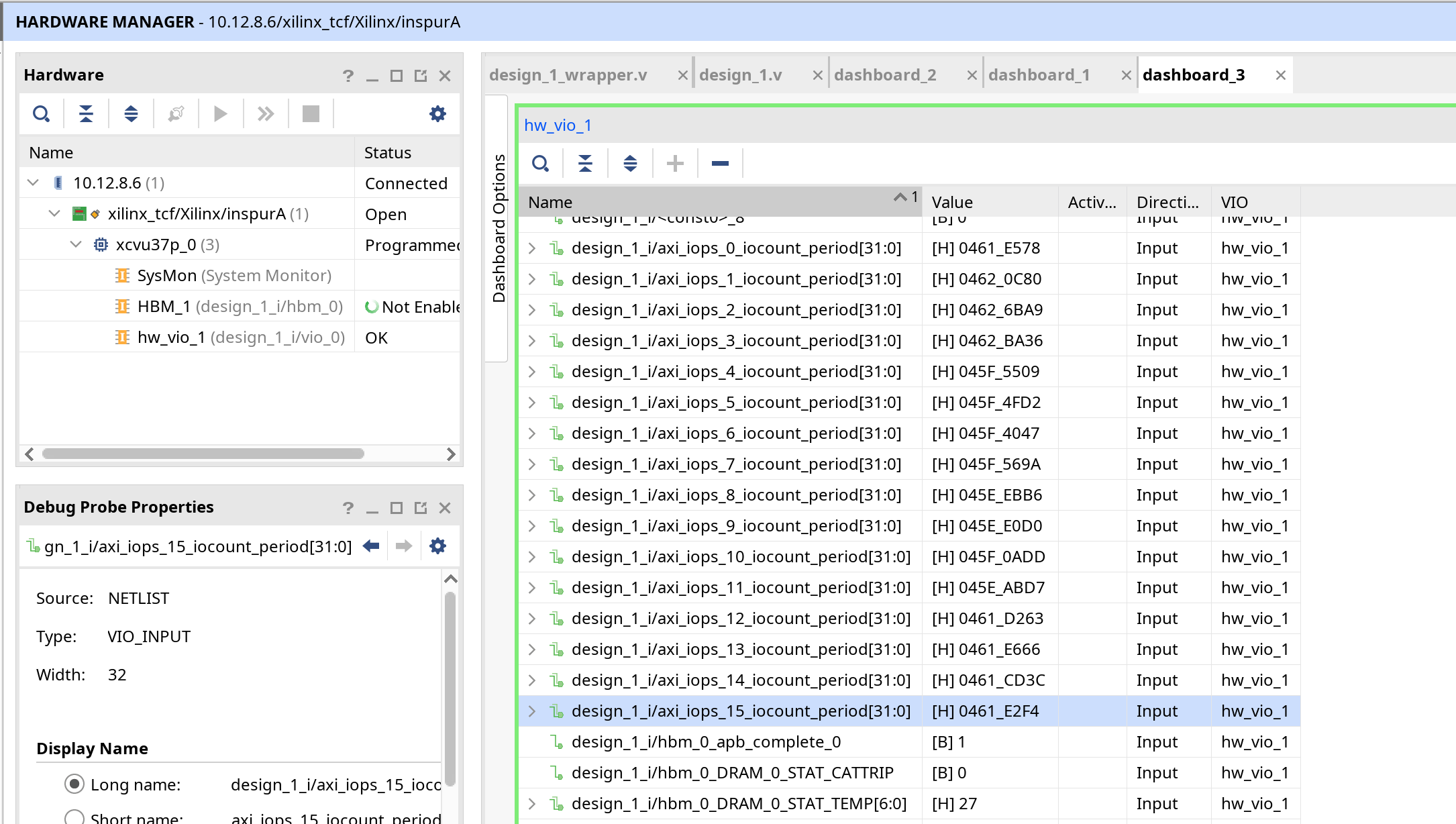
我们对这些数字求和,得到0x46093fc6,IOPS为 0x46093fc6/(2**32/(300*1000*1000))/1000/1000=82.0736,达到了82.0736 MIOPS,吞吐量为0x46093fc6*256*16/8/1000/1000/1000/(2**32/(300*1000*1000))=42.02 GB/s,且AXI通道利用率只达到了27%,应该还有继续挖掘的空间。毕竟300MHz频率下,单个HBM Stack也应该能提供153.6GB/s的带宽。
后续也和朋友讨论了一下这个结果,一个不同在于,由于Xilinx HBM的IP只提供AXI3接口,最大burst length是16,导致一次最多只能取512B的数据,但是DDR上由于MIG可以使用AXI4,所以我直接拉满了AXI的最大读写长度,一次读写4KB,或许之后还可以测一测顺序读写能力。
结论
不要小瞧DDR4的随机访问能力,也不要过度追捧HBM。
扩展阅读
在杰哥的推荐下,发现了一篇FCCM文章 Shuhai: Benchmarking High Bandwidth Memory On FPGAS 有兴趣的读者可以继续阅读。
可否展示测试过程中的block design?
HBM理论速率https://www.xilinx.com/developer/articles/maximizing-memory-bandwidth-with-vitis-and-xilinx-ultrascale-hbm-devices.html
写的好棒!