Draco(MICRO’20) Architectural and Operating System Support for System Call Security 阅读笔记
要解决的问题
Linux内核提供了seccomp来对syscall权限进行检查,被广泛应用在容器、沙盒等多种场景,例如Docker和Android。但原版seccomp的实现是通过BPF对定义的规则一条条进行检查,如下图所示,十分低效:
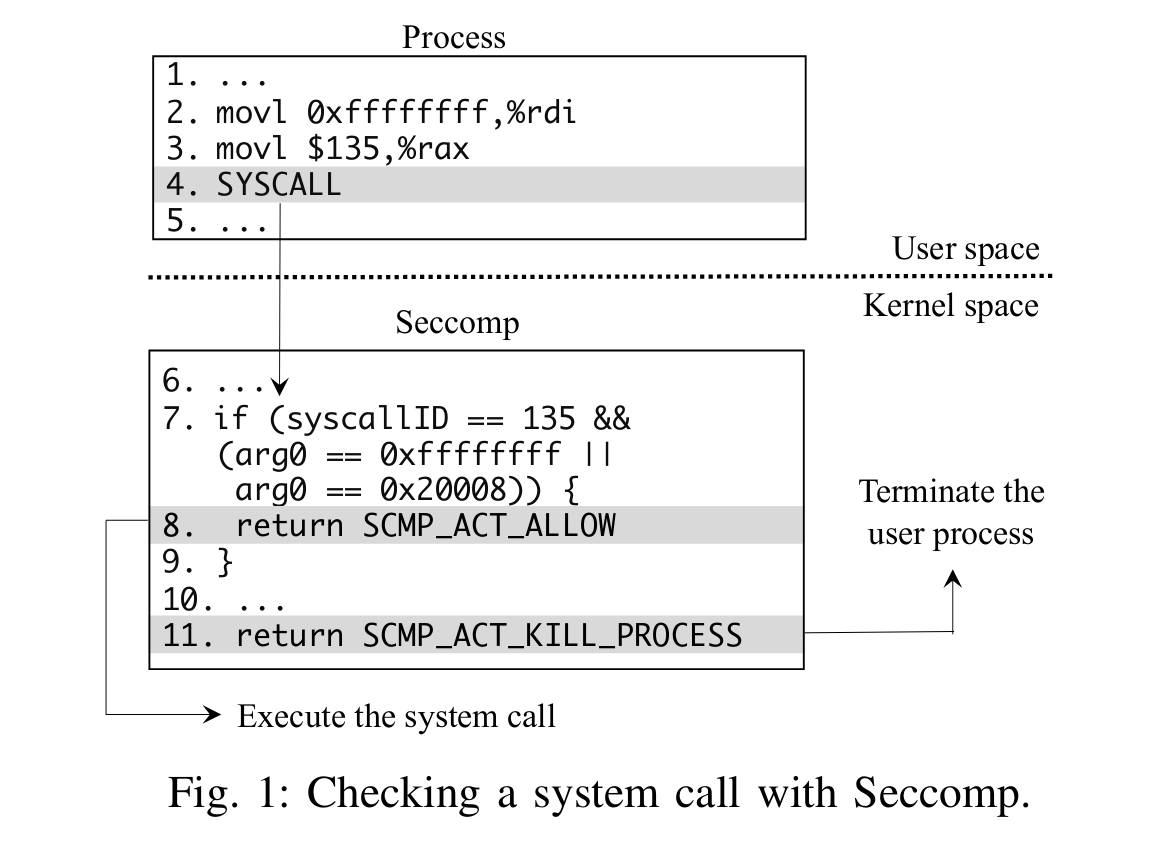
同时,作者也进行了一系列的benchmark发现这样的检查带来了较大的开销:
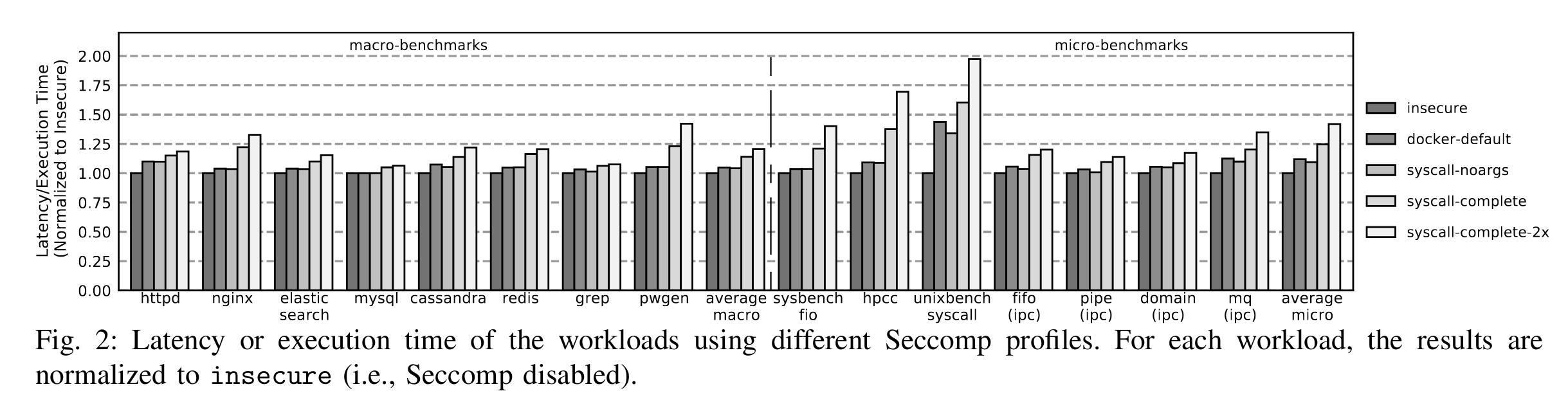
其中,左边的docker-default指的是Docker默认使用的seccomp-profile,syscall-noargs指的是使application-specific profile但只检查syscall id而不检查参数,而syscall-complete就在noargs的基础上加上参数检查,最后加上-2x的后缀表示的是这些检查复制2次,来建模更复杂的安全检查场景。
可以看出,seccomp检查带来的开销即使是对于像nginx这样的macro-benchmarks也是比较大的,但现有的seccomp使用BPF,规则十分灵活,因此需要针对这种灵活的规则设计一种加速的方法。
Observation
- 检查系统调用ID会给Docker容器中的应用带来明显(noticeable)的性能开销。
- 检查系统调用参数比只检查系统调用ID的开销大得多(significantly more expensive)。
- 规则加倍,开销加倍。
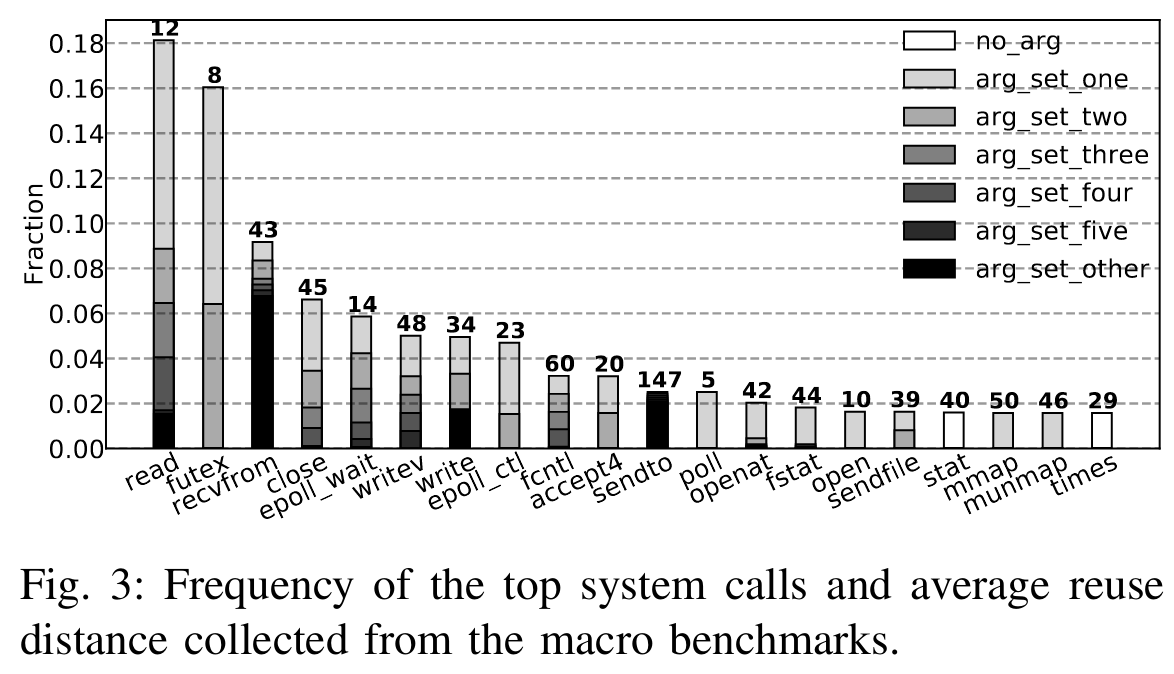
- syscall with 相同id和参数存在局部性(下图指明了实验中的距离)
解决方法
为了解决这个问题,作者引入了一个Fast Path——Check Table,结合syscall的局部性直接放行:
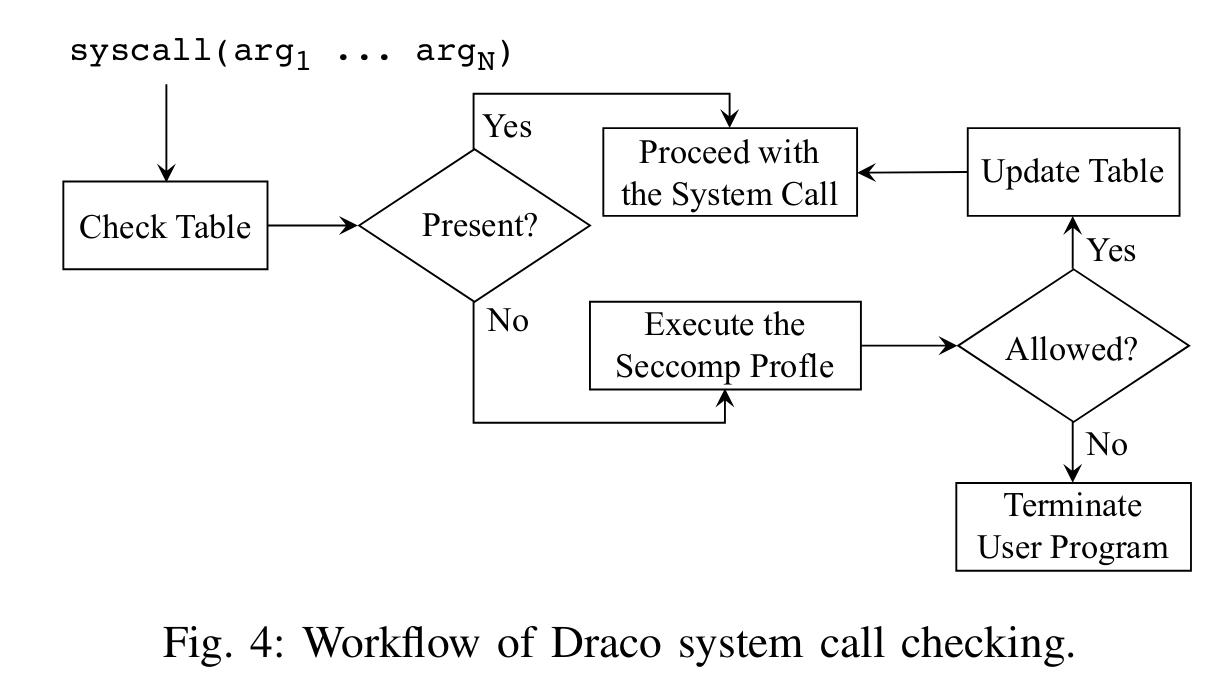
而这个Check Table的Check过程分为了软件实现与硬件实现,作者分别进行了介绍。
软件实现
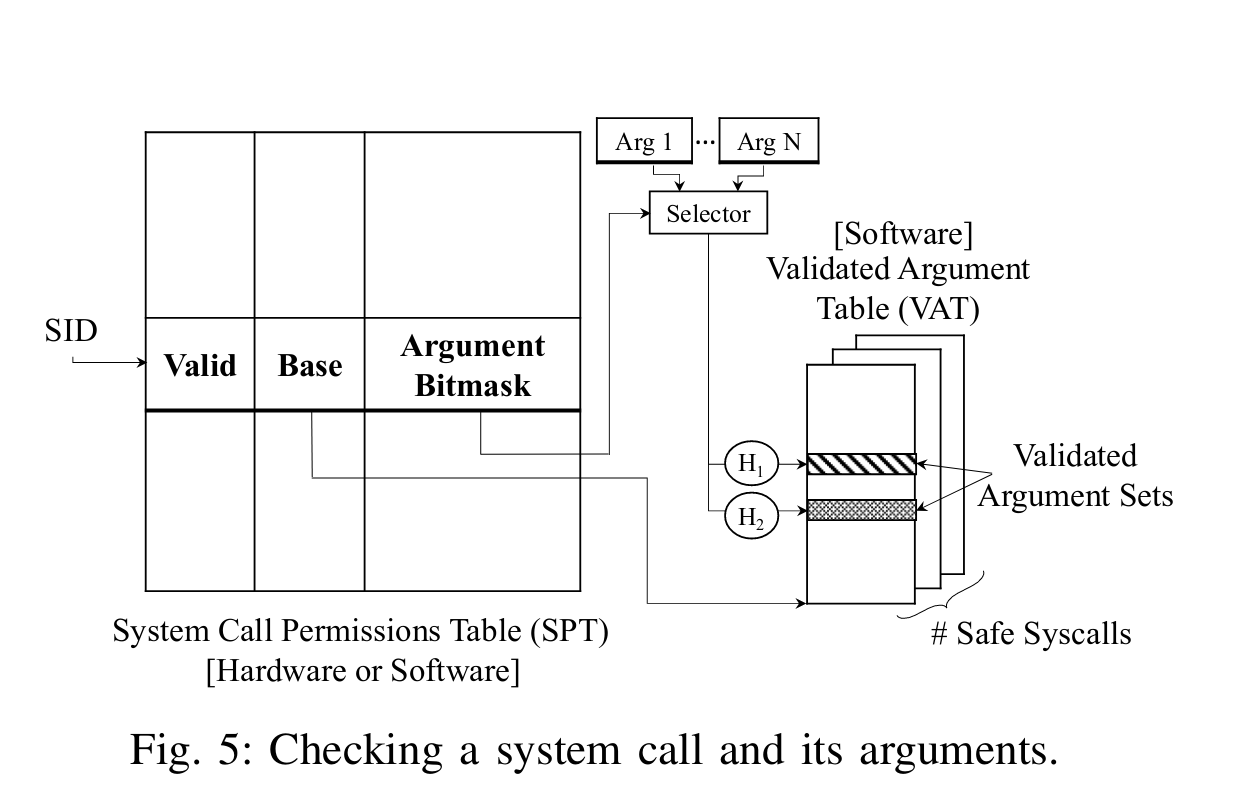
作者首先在软件上引入了System Call Permissions Table(SPT)与Validated Argument Table(VAT)。
对于SPT,该表由Syscall ID索引(SID),它的Entry数量也与Syscall ID数量相同,每个entry有Valid、Base、Argument Bitmask共3个field。对于只检查Syscall ID的情况,只需要Valid Bit来判断是否允许执行该Syscall,若不允许执行则跳按照原始的seccomp遍历规则的方式检查。
而如果不仅仅检查Syscall ID,还需要检查参数,作者引入了一个Validated Argument Table,并在每个SPT Entry引入了指向对应该Syscall的VAT基地址指针(Base),以及参数需要检查的部分的Bitmask(Argument Bitmask)。对于x86-64下使用System V AMD64 ABI,syscall最多只有6个参数(rdi, rsi, rdx, rcx, r8d, r9d),而每个参数最多8个字节,因此设计了一个48bit的mask来决定需要检查的参数的部分,然后将这些寄存器的值与bitmask进行与操作,得到Syscall的定长Key。而VAT表采用2-ary cuckoo hashing,因此通过两个Hash Function进行进行计算,然后根据其两个表项判断是否能够放行,实现了syscall检查的fast path。
硬件实现
最初的硬件实现
一个简单的实现就是把SPT放在硬件上进行实现,VAT继续放在内存中。然后当Syscall指令到达ROB的头部(即程序序中,前面的指令都执行完成,Syscall所需的参数也全部就绪),此时硬件根据SPT表判断该Syscall是否可直接放行或检查参数后放行,如果两者都不则交给OS的seccomp filter进行检查。
改进的硬件检查
最初的实现中对于需要检查参数的操作需要访问VAT表,由于该表采用2-ary cuckoo hashing,每次访问都会带来两次访存造成性能开销,尤其是在Cache未命中时。为此,作者借鉴TLB的类似结构引入了一个System Call Lookaside Buffer(SLB)的结构,提供了一个适合于硬件的Syscall检查模型。
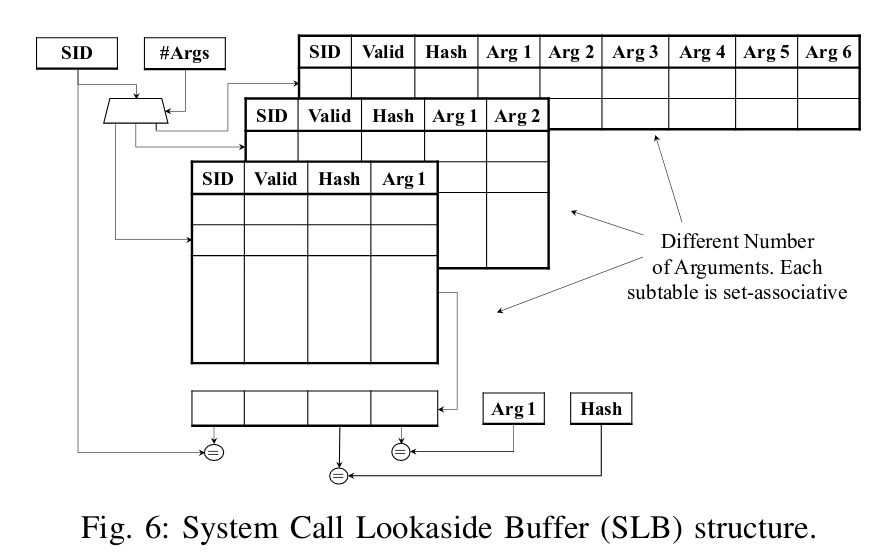
对于不同参数的Syscall的支持,作者也采用了类似许多处理器支持大页的TLB设计方法(即大页有专门的大页TLB同时进行查询与匹配),作者将参数数量不同的Syscall分为不同的表,每个表采用组相连结构(实验使用4路),且不同参数数量的Syscall使用的频率也不同,因此作者可以控制每个表的大小来避免硬件资源的浪费。
表中还有一个新的Field在前文未曾提过——Hash,因为作者在引入SLB结构时依然保留了硬件上的STB表的结构,而Hash就是STB表中对应掩码与参数Bitwise-And后的结果按照前文的H1或H2的Hash函数进行Hash的结果。
(P.S. 细心的读者读到这可能会发现一个问题,为什么已经有了Args本身还需要存储Hash,这就与之后要提到的预测功能有关。)
最后,整个流程如下:
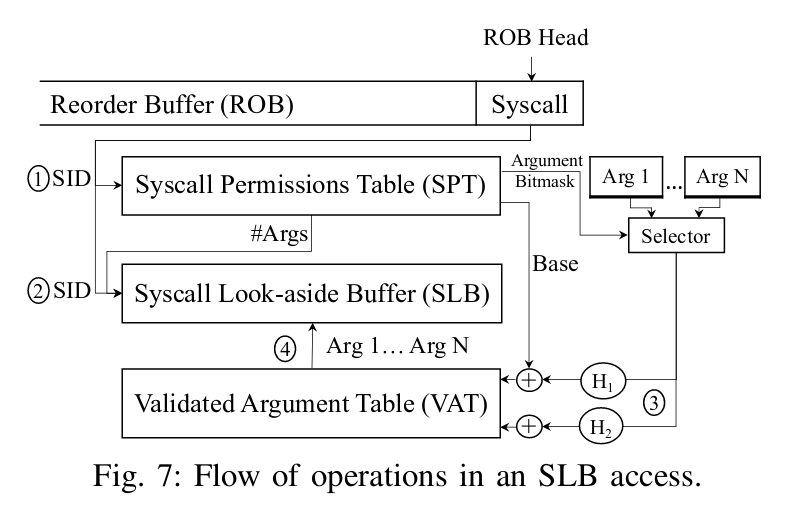
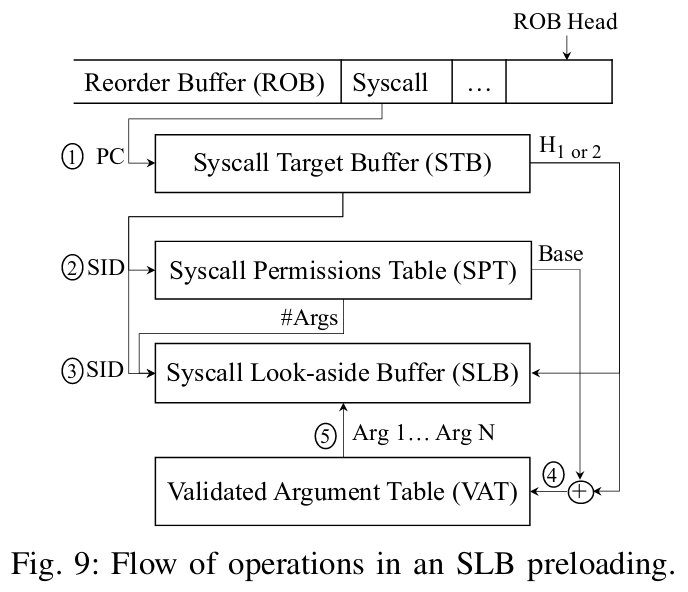
而有了SLB还没有结束,对于乱序处理器而言,如果等到syscall走到ROB头能够执行的时候再去做检查,那么一旦SLB Miss还是会带来比较大的开销。因此作者借鉴了分支预测的BTB的思想,提出了一个STB,用于syscall指令刚进入ROB时就对后续需要访问的SLB进行prefetch,结构如下:
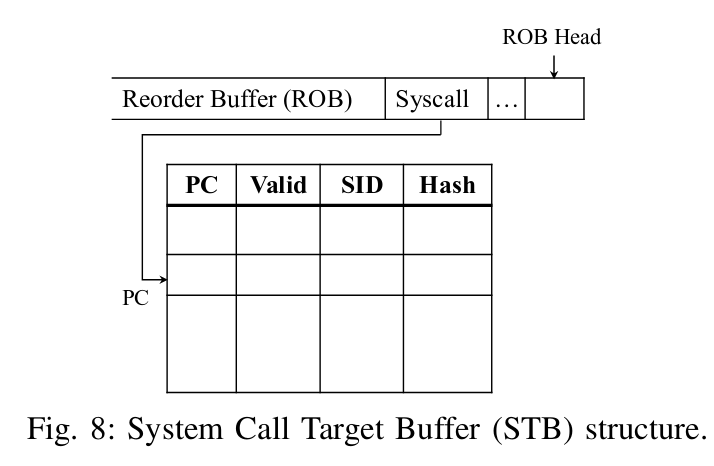
因为syscall指令刚进入ROB时,Syscall所需要的Syscall ID和参数的值可能都还没计算出来(不懂为什么的读者建议复习一下乱序处理器的原理),但同一PC下的Syscall一般有相同的Syscall ID以及可能相同的参数,因此基于这个开发的STB表就可以记录过去该PC的SID和Hash值,用于检查SLB中是否有所需要的内容,如果没有,则可以从内存的VAT提前prefetch,利用硬件上的并行最大程度地减小Syscall检查开销。
整个prefetch流程如下:
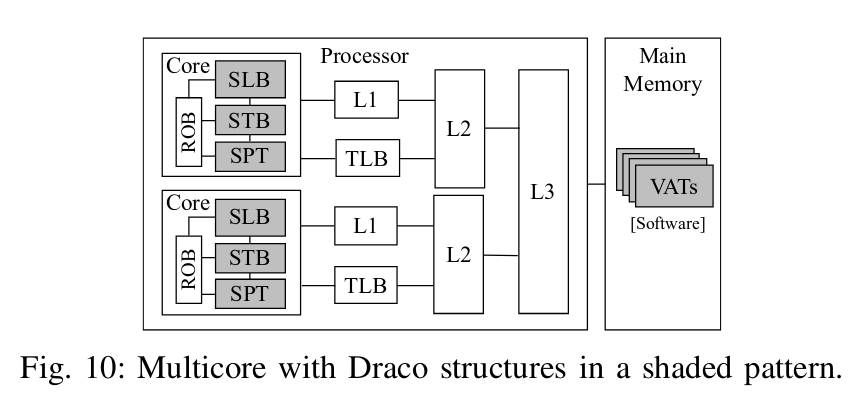
最后,基于这些结构都是per core的,因此多核处理器中整体设计如下:
细节
Data Coherence
作者没有为这三个结构提供cross crore coherent支持,因为system call filters并不会在进程运行时修改,因此Draco只提供了一次清零这三个结构的操作。
上下文切换
作者的设计会在上下文切换期间清空这三个结构,为了降低上下文切换后的start-up overhead,作者让OS在上下文切换的时候保存SPT大内存中,但SPT很大,为了减小需要保存的SPT,作者给SPT增加了Access bit,并定期(e.g. every 500us)清空,以确保只保留了最近常用的syscall。
侧信道
显然,prefetch SLB涉及到VAT的读取,必然带来缓存侧信道,但其实缓解的方法很多,例如Cache分割等,但作者认为单纯使用seccomp也同样带来了侧信道,因此最后认为这样的side channel是beyond the scope of this paper。
Evaluation
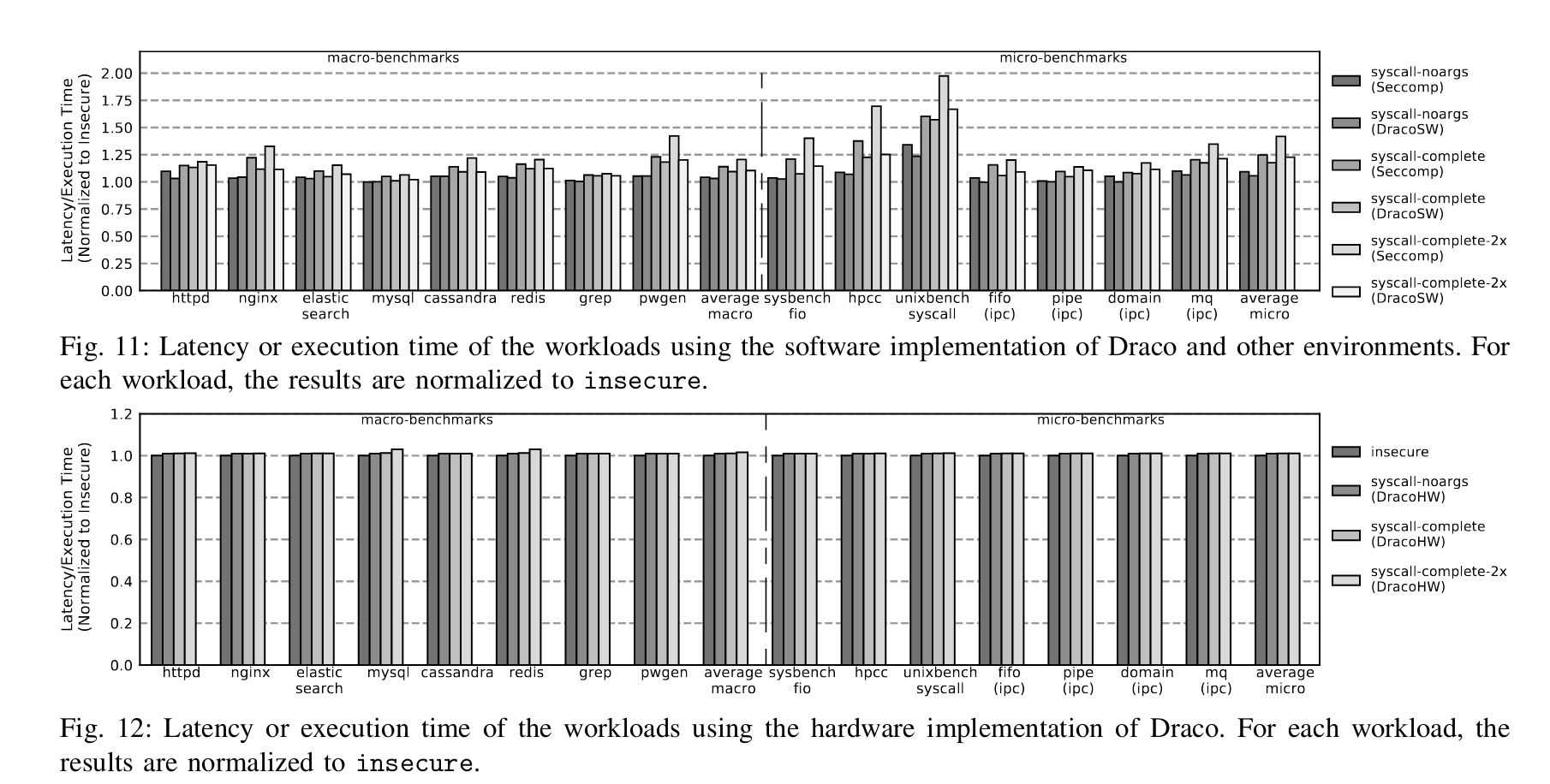
硬件实现上,作者使用了一个周期级的全系统模拟器——Simics。性能大概如图:
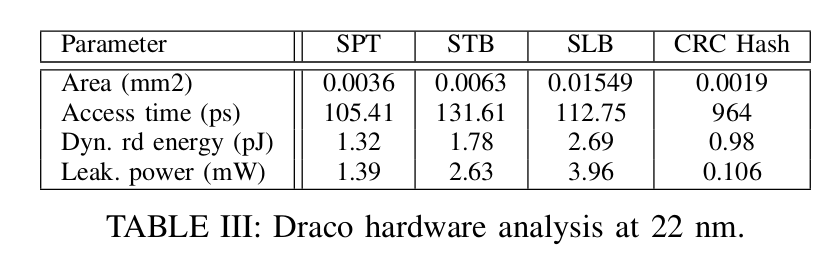
作者还对22nm工艺下实现这些结构所需要的面积、功耗等进行了评估:
点评
这是我见到的一篇比较特别的软硬件协同安全的论文,和许多关于内存安全的文章不同之处在于,它发现了许多人诟病的seccomp性能问题,并在不破坏seccomp使用BPF规则的兼容性的情况下根据系统调用的局部性提出了基于SPT+VAT的软件fast path,并在充分考虑了乱序处理器中ROB这样的特性,借鉴了TLB、BTB等我们熟知的硬件结构特性后,提出了SLB与STB结构进行Syscall的安全检查和检查器的prefetch实现软硬件协同加速,在实验条件下,安全检查的开销几乎降低到了与没有安全检查相当的水平。
值得一提的是,从作者的主页看出,Draco的软件实现已被Linux内核主线接收。(能做Practical的工作真好啊!)
我总结出以下启示:
- 许多其他的filter也许都可以套用这种方法进行加速。无论是软件还是硬件。
- uArch的知识对于System的研究至关重要。这篇文章其实对于了解uArch的人读起来非常舒服,与其他一些hw/sw co-design的安全方案在五级流水核上的实现相比这更加符合实际。
- 如果觉得内存安全很难做出新东西了,可以探索一些新领域,例如像内核某个高开销的安全检查的软硬件协同优化。
Jovan+cuckoo hashing+intel extension真好啊