背景 m1luf0 在她的 OnePlus 12 上安装了 Island 创建隔离的 Work Profile,然后进行了一些 App 的 Clone 后 Destroy 再次重新创建,在创建过程中手机就自动重启,接着开机后,每次输入密码大概 2-4s 左右的时间又会自动重启(前3次只重启…
Opus 4.6 级别的 AI 真的可以取代程序员吗?
背景 因为自 Opus 4.6 以来的 AI 能力快速提升,使得自己效率得到了充分提高,便开启好几个 AI Agent 同时进行各种各样的 Project(曾经梦想着毕业后带一个团队来干很多心里认为有趣的idea,结果在 AI 时代提前低成本实现了),有自己论文的完善,也有新论文的实现以及探索,还有一些大工程性质的玩具。然而,我很快发现,如果当前 AI 的上下文能力或者记忆能力不能在现在的 Baseline 上指数级提升,对复杂的任务依然只有加速能力而非完全的取代能力。 曾经在电视上看到过脑部受伤,海马体受损无法产生新记忆的人(如“笔记本男孩”…
裸 die 芯片散热请务必使用相变硅脂
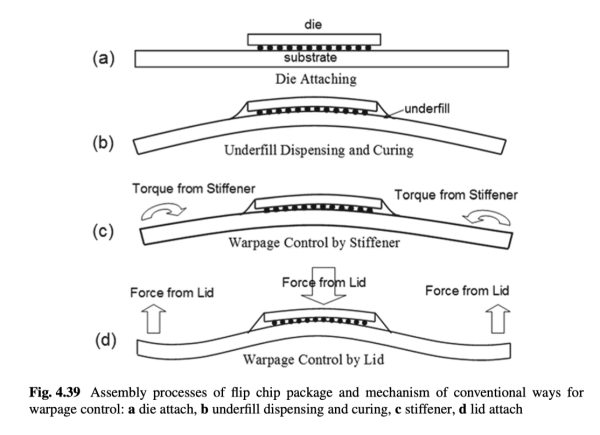
背景 自己在京东上买的磐镭YO-1 AMD Strix Halo 小主机在短短半年的时间内经历了2次高温死机问题的售后。而在上个月跑一些自己的研究代码测性能期间,我发现了严重的单核降频问题(5.1GHz Turbo 跑出来只有 4.6GHz),最终定位到问题在于,原厂普通硅脂的pump-out effect(蹦出效应)导致的问题。 经过 2025.6.6 购入小主机 2025.6.18 经历第一次高负载死机,京东换新 2025.10.8 经历第二次高负载死机,京东换新 后面几个月持续安稳…
AI 提高了效率,喜欢打开黑盒的 hobbyist 怎么办
背景 我很幸运我是一个在很小的时候就找到了自己喜好的人——探索世界,打开一个个我曾经认为的黑盒子。 我也很幸运,从小学就会自己折腾计算机,翻看 Windows 的系统文件,自己学编程,组装电脑,硬件 Mod,折腾 Linux 桌面,甚至到最后学机器人参加比赛,以及玩 Arduino 单片机,这些事情给了我计算机以及程序逻辑的最早启蒙。 我同样很幸运,在高中的时候开始学 OI,最后拿到省一等奖参加自主招生,选了省一等奖可以满足前两个专业志愿的学校保住了我一定能学 CS ,再到后来继续参加 ICPC 比赛拿到 EC-Final 银牌,NSCSCC…

ZRAM might be a budget solution for high-priced DRAM
Background As DRAM prices continue to rise, many users are exploring alternative solutions to manage memory more efficiently….
AMD Strix Halo 上运行 ROCm 7.1 + PyTorch 踩坑小记
背景 最近打算尝试微调 LLM 做一些科研有关的工作,但毕竟我不是做 AI 相关方向的因此自己并没有合适的 GPU 。目前多数开箱即用的模型训练都工作在 FP16 这样的精度(虽然有很多很多低精度训练的研究了),而不是推理常见的 INT4,因此仅仅 7B 参数完整载入就需要 14G 的 VRAM,再加上微调模型中所需的数据又需要额外的 VRAM,手里实在没有 VRAM…

RISC-V 通用处理器,未来在哪呢
前言 相信大家也看到了,RISC-V 通用处理器生态圈的现状并不太平。 它市场竞争力低吗?确实! 我们能改变吗?我相信还有机会! 注:本文仅代表本人立场与观点,不代表任何组织、开源社区。 现状是什么样呢? 基础的 Linux 内核、发行版以及大量的开源软件支持 QEMU 级别单核性能的现存硬件 碎片化的 ISA 遇上想建立新纪元的发行版 满足 Bug-free &&…
Is TSO a historical burden for modern CPU? Case study on Apple M1
Is TSO a historical burden for modern CPU? Preface x86-TSO (Total Store Order) is the memory consistency model…

CCS 2025 Travel Notes
Preface I recently traveled to Taipei for the ACM CCS 2025. It’s been 14 years since my last…
Back to Top