聊聊内存序
最近读完了 A Primer on Memory Consistency and Cache Coherence这本书,写一篇文章结合我个人了解的其他知识总结一下内存序。
文章假定读者学习了基本的体系结构。
概念
Cache Coherence
相信大家对Cache有一个基本的理解。但这里需要引出一个新的概念,共享内存中的Private Cache。
即使是简单的单核处理器,往往L1 I-Cache与D-Cache也是Private的。因为IFU(取指单元)与LSU(访存单元)通常分布在处理器流水线的不同阶段,它们可能需要同时访问。既然是Private,这个时候如果我们通过访存指令写入了一些指令(通过D-Cache)到某个内存地址,而这个地址已经在I-Cache中,结果就在取指时有可能取到旧值,如何解决这一问题?
也许L1 I-Cache与D-Cache还可以通过双端口、仲裁器等方式进行共享,并通过一系列Buffer的设计来减少冲突,甚至可以让软件手动添加Cache维护的指令(例如RISC-V的CMO的一系列扩展,MIPS的CACHE指令。甚至使用类似RISC-V上fence.i这样本质是用于刷新流水线的指令,来当做I-D Cache同步指令去写回所有D-Cache并失效所有I-Cache也是一种简单核常用的做法)。但到了多核的场景,每个CPU核心可能距离较远,此时再让所有CPU访问一个共享的Cache,电路上的延迟也不可避免增加,影响效率。
此外,在我们的计算机上,除了各个处理器核心,可能还有能够访问内存的DMA外设,而DMA写入的数据所对应的地址若在某个Private Cache中有效依然有这样的问题。
因此,在SMP架构中,我们希望硬件能够实现Cache Coherence,这样能够大大降低编程难度。当然,也存在不保证缓存一致性的硬件架构,例如我们的GPU就采用这样的方式,而这就导致开发者需要更多地去关注程序中每个数据的共享域。这里我们尚不讨论这些情况。
Cache Coherence需要做的就是让Cache变为透明,将写操作能够eventually传播到其他处理器(也包括一个处理器核中从L1 D-Cache传播到L1 I-Cache)。
Memory Consistency
细心的读者会发现前文强调了eventually,这与要引入的Memory Consistency有关。不了解有关基础的读者可能会认为一个核心上产生的写操作是跟随程序序传播到其他核心的,这一做法很符合直觉。但别忘了,我们的编译器优化会对访存进行重排,我们的处理器采用乱序多发射的架构一样会对Load/Store进行重排。除了乱序多发射的重排外,处理器还有很多性能优化措施。处理器总线的结构也有各种形式,例如Intel Core的Ringbus,Intel Xeon上的2D Mesh结构。我们如果继续保证写传播到其他核心一定跟随程序序且满足一个全局顺序,那么对于硬件来说会增加很大的开销。而解决硬件这一开销的一种做法就是让Load/Store行为变得“反直觉”,允许硬件对内存操作进行重排序,并添加内存屏障指令(如RISC-V上的fence,ARM上的DMB/DSB/ISB,x86上的lfence/sfence/mfence),在软件要求某些操作不能重排序时,通过内存屏障指令显式告诉硬件。
因此,Memory Consistency在定义上也叫Memory Consistency Model或Memory Model,它定义的是在共享内存中Load/Store的行为,不涉及缓存与一致性的部分。
而对于开发者来说,需要熟悉硬件的Consistency模型(通常指令集架构(ISA)就会定义一个最宽松的内存序模型),而使用这个ISA设计/制造的硬件通常又比ISA定义的内存序更严格(更少的reorder情况,更加保序)。因此,软件开发者只需要确保自己的软件能够在ISA定义的这个最弱的Consistency模型上正确工作而不出现Data race,那么在基于这个ISA的硬件上也一定能正确工作。
内存序
以下讨论基于多个CPU核心共享内存的场景。一个核心观察自身的读写永远是符合程序序的。
在引出内存序(Memory Ordering)之前,我们先思考下这个代码:
int x = 0;
int y = 0;
void t1() {
y = 1;
int res = x;
printf("x=%d\n",res);
}
void t2() {
x = 1;
int res = y;
printf("y=%d\n",res);
}提问,如果编译器不进行任何优化,静态区内存分配将x和y的地址相距很远(不抬杠它是否在同一个Cache Line的问题),如果t1与t2运行在不同的CPU核心上,有可能出现x=0&&y=0吗?
如果我们认为所有访存操作都是单线程的,那么非常显然,我们得到程序的输出只有3种,分别是(x,y)={(1,1),(1,0),(0,1)}。然而在一些内存序中,出现(x,y)=(0,0)的结果是被允许的。
而处理器这么做的原因是为了性能优化。在许多更弱内存序的ISA上(例如ARM、RISC-V),下面的介绍或许会让部分读者震惊,并开始思考软件如何适配的问题。
Sequential Consistency
现在,我们定义一种内存序,称为Sequential Consistency,以下简称SC,我们可以简单认为所有内存操作都是单线程。
同时我们定义每个核心的程序序为p,内存操作可被其它核心观测的顺序为m。用L(x)表示Load(x)地址,用S(x)表示Store(x)地址,则对于SC内存序,有以下约束:
-
所有的核心都按照程序序将Load/Store插入到全局内存序(m)中。对于任意两个Load/Store请求,无论他们地址相同或不同均是如此。
我们可以分为以下几种情况:
- If L(a) <p L(b) ⇒ L(a) <m L(b) / Load to Load /
- If L(a) <p S(b) ⇒ L(a) <m S(b) / Load to Store /
- If S(a) <p L(b) ⇒ S(a) <m L(b) / Store to Load /
- If S(a) <p S(b) ⇒ S(a) <m S(b) / Store to Store /
-
对于每个Load,都得到该地址在全局内存序m中最后一次Store的结果。
- L(a) = Value of MAX <m {S(a) | S(a) <m L(a)}
其中MAX <m定义为内存序中的最新。
在这种模型中,程序序=全局内存序,非常符合我们直觉。就好像所有的核心同时只有一个可以访存,或系统中对于同一个地址空间只能运行一个线程通过上下文切换一样。
RMW(Read-Modify-Write)怎么办?
即使是SC的内存序,它也只保证了全局的Load和Store之间有个顺序,这就带来一种很常见的Data Race,就是RMW的场景。这一类问题也被称为ABA Problem。
例如以下代码:
int sum = 0;
void t1() {
sum += 1
}
void t2() {
sum += 2;
}假设t1和t2同时在不同处理器上运行,我们期望t1和t2执行完成后,sum值为3。
但需要注意的是,直接在C语言中编写+=这样的运算符,并不会保证其操作的原子性,对于编译器而言,它看到的是:
- x=Load(sum)
- x=x+1
- Store(sum,x)
这个时候,就需要处理器提供RMW指令来解决这一问题。而高级编程语言也有提供类似的方法,例如C11的atomic_相关函数,C++11的std::atomic。
对于硬件而言,就需要提供RMW相关指令:
例如对于x86,有lock前缀的指令,例如lock add等。还有xchg等指令也会保证操作的原子性。
对于MIPS,提供了ll/sc指令对,ll意为Load-Linked,sc意为Store-Conditional。当我们要进行一系列RMW操作时,可以先使用ll指令读取要修改的数据,此时CPU硬件上会记录ll操作的地址,然后执行一系列运算指令完成modify部分的操作。sc指令是一条特殊的指令,相比常规的sw增加了一个返回值寄存器,在sc时检查该地址是否被其他核心/DMA控制器修改过,若没有,则SC成功,否则SC失败。SC成功与失败是通过该返回值寄存器返回给程序的,这样程序就可以写一个简单的循环,尝试LL/SC序列,直到成功即可。(由于CPU同时能存储的跟踪地址有限,所以MIPS上ll/sc并不能nested。)
在RISC-V上,既有ll/sc等价的指令lr/sc(Load-Reserved/Store-Conditional),也有x86上lock前缀等价物,例如amoadd、amoswap等。
aarch64基本指令集提供LDXR/SDXR等类似lr/sc的指令,自ARMv8.1起提供了LDADD等类似lock add的指令。
这些RMW指令也常用于并发编程中实现无锁数据结构。
Total Store Order
为什么需要提出TSO
我们试想一下,如果处理器的内存序必须为SC,在硬件实现的性能上会有什么坏处?
即使是单核的处理器,我们往往也会设计一个写缓冲区(Store Buffer)。即使我们的Cache采用Writeback+Write Allocate的策略,当写缺失的时候我们需要向更高级缓存或者是LLC(Last Level Cache)/内存取回该缓存行。尽管读操作依然有这个问题,但读操作的暂停涉及到数据依赖的问题,此时我们不得不停下来(当然,现代高性能处理器用的寄存器值预测/Load结果预测就是另一回事了)。而对于写操作,我们不仅可以使用一个缓冲区进行缓冲,还可以对于Store->Load进行转发,这样刚刚执行的Store还未提交给内存子系统(Cache、内存等组件)前,马上读取刚刚写的结果就可以由Store Buffer转发,以实现处理器性能的优化。
此外,还有一种情况就是连续的MMIO(Uncached)写,自己在打龙芯杯比赛(NSCSCC)期间,还亲眼见证了龙芯杯团队赛的性能测试中有两个测试用例会往一个写之前不需要任何读操作的串口设备写字符串(毕竟是仿真调试用的,只要仿真能输出就行,所以不需要像UART 16550、UARTLite一样实现FIFO并让软件判断FIFO是否满再写),且访问频率达到了20-30条指令一次,这就导致如果每次都这么暂停流水线,等待写操作完成再继续,会导致非常严重的流水线停顿。而使用一个Store Buffer就可以解决这一问题,当然,这种情况下不可进行写转发(毕竟MMIO外设不是内存),也不可在Store完成前继续发出Load,否则就违背了IO必须保序的规则(请读者不要抬杠Write Combine这种特殊情况)。
而到了多核的场景,如果我们需要继续保持全局内存序严格等于程序序,那么Store Buffer的实现就相当困难。而如果删掉Store Buffer,性能会受到影响。此时一个折中的方法产生,就是在Store Buffer中结合缓存一致性协议的消息观测是否出现内存序Violation,如果出现,就进行一系列复杂的处理使之满足内存序定义。MIPS R10K就采用了这种方式。但这其实大大增加了处理器复杂程度。
因此,我们希望提出一种可以在添加了Store Buffer后,减小处理因Store Buffer造成violate SC内存序对性能影响的内存序模型,这就有了TSO。这也是x86、x86-64上使用的内存序模型。
TSO定义
现在,我们规范地定义一种名为Total Store Order(下称TSO)的内存序,如下:
-
所有的核心都按照程序序将Load/Store插入到全局内存序(m)中。对于任意两个Load/Store请求,无论他们地址相同或不同均是如此。
我们可以分为以下几种情况:
- If L(a) <p L(b) ⇒ L(a) <m L(b) / Load to Load /
- If L(a) <p S(b) ⇒ L(a) <m S(b) / Load to Store /
If S(a) <p L(b) ⇒ S(a) <m L(b) / Store to Load /- If S(a) <p S(b) ⇒ S(a) <m S(b) / Store to Store /
可以注意到,这里相比SC,删去了Store to Load保序的断言,因此TSO允许Store to Load的reorder。
- 对于每个Load,都得到该地址在全局内存序m中最后一次Store的结果,或经由本核心已在Store Buffer的结果转发。
- L(a) = Value of MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)}
相比SC,这里或上了S(a) <p L(a)部分。
因此,由于允许Store to Load的reorder(也就是Store操作可能被延迟执行),我们在以下测试中可能观察到(x,y)=(0,0)的情况:
int x = 0;
int y = 0;
void t1() {
y = 1;
int res = x;
printf("x=%d\n",res);
}
void t2() {
x = 1;
int res = y;
printf("y=%d\n",res);
}同步互斥怎么办?
细心的读者看到这一定会思考一个问题,我们在线程同步中会增加很多同步互斥的锁,如果允许Store延迟,那么如何确保锁的原子性呢?
-
RMW指令保证了访问锁本身的原子性
我们假设一个互斥锁用1表示被占用的状态,0表示自由状态,那么使用任意swap用途的RMW指令/RMW指令序列将该锁的值写为1,并判断返回值是否为0。毕竟RMW指令已经保证了整个过程只有一个Writer。
-
Peterson’s Algorithm
不了解该算法的读者可以先查阅Wikipedia。
在比SC更弱的内存序的ISA/处理器上使用形如Peterson’s Algorithm这样的互斥方法时,我们需要保证每个内存修改都提交到其他核,并在load前能够接收其它核提交的修改,才能继续执行下一步的load/store。这时我们需要插入我们所使用的ISA相对应的Memory Barrier。
例如对于x86,就可以在每一步load/store之前以及之后都添加mfence指令。它会确保这个指令之前的所有load/store都传播到其他核心,再进行下一步操作。
RMC
RMC=>Relaxed Memory Consistency。
TSO有何不足?
回顾内存序模型从SC变为TSO,是为了适应Store Buffer的加入。
而假如处理器由顺序单发射变为乱序多发射,且同时发射的多条访存指令可能有部分已经在Cache中可以被立即执行完毕,而另一部分可能需要等待Cache向总线请求才能继续。这种时候就可能出现即使是单个线程的Load/Store也被打乱的情况。对于单核处理器而言,只需要在这些访存请求上做一个Reorder Buffer,处理正确的数据依赖即可。
但如果处理器没有Store Buffer,或是在乱序Load时没有监听新的写传播信息到达,就可能出现我们在定义SC内存序中提到的四种乱序均发生的情况。
RMC的内存屏障
我们以RISC-V ISA为例来介绍RMC的内存屏障。
在RMC中,内存屏障也变得更加复杂。例如RISC-V提供了fence指令,其指令本身还有8位可以变化的部分。分别是FENCE前后的I/O/R/W,对应的是IO读/IO写/内存读/内存写(需要注意的是,RISC-V的IO与内存地址空间的区别主要采用一个固定的PMA,基于页表控制的Svpbmt只是一个扩展,且IO在Svpbmt中也提供了idempotent,weakly-ordered类型)。
这就导致,我们使用一些互斥锁时,互斥锁除了自身需要保序外,互斥锁到临界区之间的内存读写需要也需要严格保序,这就导致我们同样需要在进入临界区之前使用fence指令来确保之前对锁的操作已生效,且后续的Load/Store不能被提前。
也正因此,RISC-V在原子操作指令中,还添加了2个bit,分别是aq和rl,分别代表Acquire和Release。
其中:
- Acquire表示不允许其后续的Load/Store操作重排到Acquire前面
- Release表示不允许前面的Load/Store操作重排到Release前面
这时应该有部分读者已经发现,Acquire屏障恰好是我们在一个互斥锁中,获取锁进入临界区的屏障,而Release屏障也恰好是在一个互斥锁中临界区结束,需要释放锁时需要的内存屏障。那么我们也可以很显然发现RISC-V指令集在amo指令上添加aq/rl位的好处,让我们在做原子操作的同时就可以同时插入内存序的hint,减少一条fence指令的空间。
SC for DRF
Sequential Consistency for Data-Race-Free Programs是本书的一个很重要的概念。我们前文已经介绍了硬件提供的各式各样的内存屏障指令以及原子操作指令。在这种情况下,程序员只需要通过这些指令实现正确的同步,那么程序的执行是与SC内存序无异的。
Causality and Write Atomicty
Causality:If I see it and tell you about it, then you will see it too.
Write Atomicity: a core’s store is logically seen by all other cores at once.
Write Atomicity
我们讨论Write Atomicity问题,是否存在一个内存写入对于除写者核心以外的核心到达的顺序不同?
很显然,这种情况是可以发生的,非常典型的就是CPU的SMT(超线程)。一个核下的其他线程更容易比其他核更快观测到写者线程产生的修改。
但如果CPU不保证Write Atomicity,会大大增加编程难度,在ARMv7的文档中有该问题的举例以及介绍。
但到了ARMv8中,ARM强化了内存序实现,增加了Multi-copy Atomicity,在AMBA文档中提到了这个修改。
对于RISC-V,RVWMO也同样要求Write Atomicity。因此我们在现代的主流架构上或许很难见到该问题了。
我们也可以很显然推导出,Write Atomicity充分满足Causality,但不必要。
Causality
我们来解释一下为什么Causality不一定需要Write Atomicity。
int x = 0;
int y = 0;
void t1() {
x = 1;
}
void t2() {
y = 2;
}
void t3() {
print(x);
fence();
print(y);
}
void t4() {
print(y);
fence();
print(x);
}对于Write Atomicity,我们一定需要满足写入操作有一个全局偏序,因此这还限定了我们在t3、t4读取时,不应该出现一个只能读到x的新值且一个只能读到y的新值这样的情况。但我们很容易构造出一种满足Causality却不满足Write Atomicity的实际硬件。
内存序是否带来软件移植障碍?
是,而且在软件从x86移植到ARM这样的架构时发生了非常多了,一个典型的例子。
二进制翻译
在RMC上运行使用TSO编写的程序
看完了以上关于内存序的介绍,相信大家应该十分好奇,在一种更弱的内存序模型的ISA上运行假定了更强的内存序编写的软件,翻译需要考虑什么问题?
显然,对于严格正确的二进制翻译,在无法确定一个数据是否要被其他线程共享时,添加Memory Barrier使其等价是必要的。但这会导致性能受到巨大的影响。
我们可以来看看主流的二进制翻译怎么做:
- QEMU-TCG:插入大量Barrier,性能不好但是正确性得到保证。
- Apple Rosetta 2:Apple M1硬件支持TSO模式,并可通过CSR配置,对于运行x86软件的核心将TSO开启,这样翻译时可省略不必要的Memory Barrier。这是非常高效的软硬件协同二进制翻译
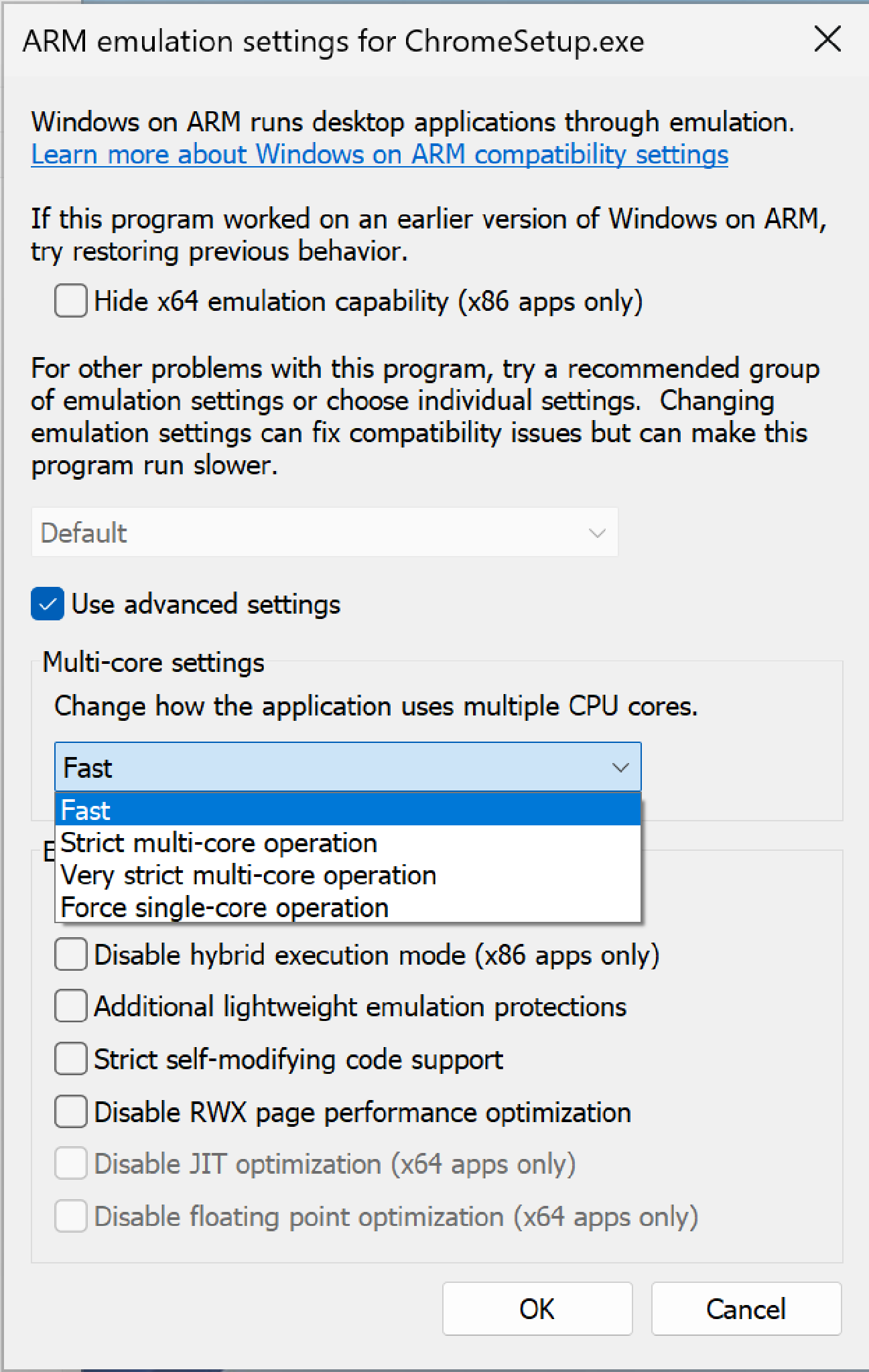
- XTAJIT(Windows on ARM):默认不插Barrier,用户如果遇到兼容性问题时提供多种选项(例如退化到单核运行或是不同等级的插入Barrier的方式运行)
“Release表示不允许前面的Load/Store操作重排到Release前面”
这里的Release操作,应该是表达指令前的Load/Store不可重排到Release的后面?