sPIN: High-performance streaming Processing in the Network 阅读笔记
这是一篇来自 SCPL@ETHZ 组在 SC’17 上的一篇文章。主要想法是在 RDMA 网卡上加入一个处理器用来 Offloading 一部分数据移动任务,并在 LogGOPSim 与 gem5 上进行了实验。
Motivation
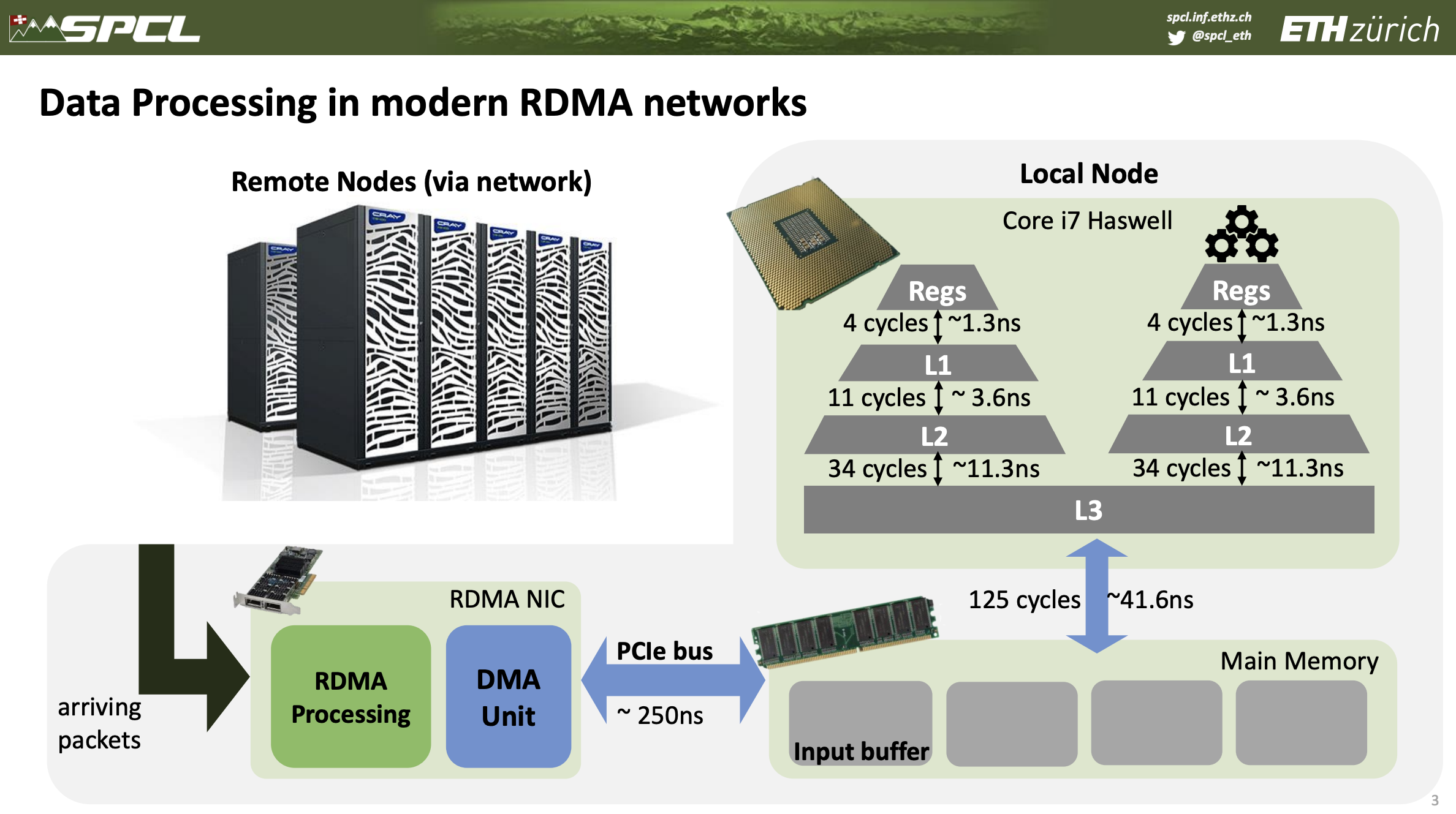
当前高能效处理器组成的高度可扩展的系统发展带来了总线互联的压力。例如在 400Gbps 的网络中,一个 64B 的数据包的传输时间只有 1.2ns (不考虑帧间距),而即使有了 RDMA 解决了频繁的 CPU 中断让网卡直接访问内存也造成了一些瓶颈。例如 RDMA 将数据接收到一段内存的缓冲区,然后 CPU 上的应用读取来完成处理,然后写回一段发送缓冲区再发送到网络上,在上下文切换与内存带宽以及内存延迟层面都带来了巨大的 Overhead 。
这里引用一张作者 Talk 中的图:
为了解决这个问题,作者提出了sPIN(SC’17),其实就是在网卡上加了数个小处理器来专门处理数据移动的问题,后续sPIN还提出了RISC-V核实现叫做PsPIN(ISCA’21)。
Design
大致架构图如下,其工作主要是给网卡加入了HPU(handler processing units):
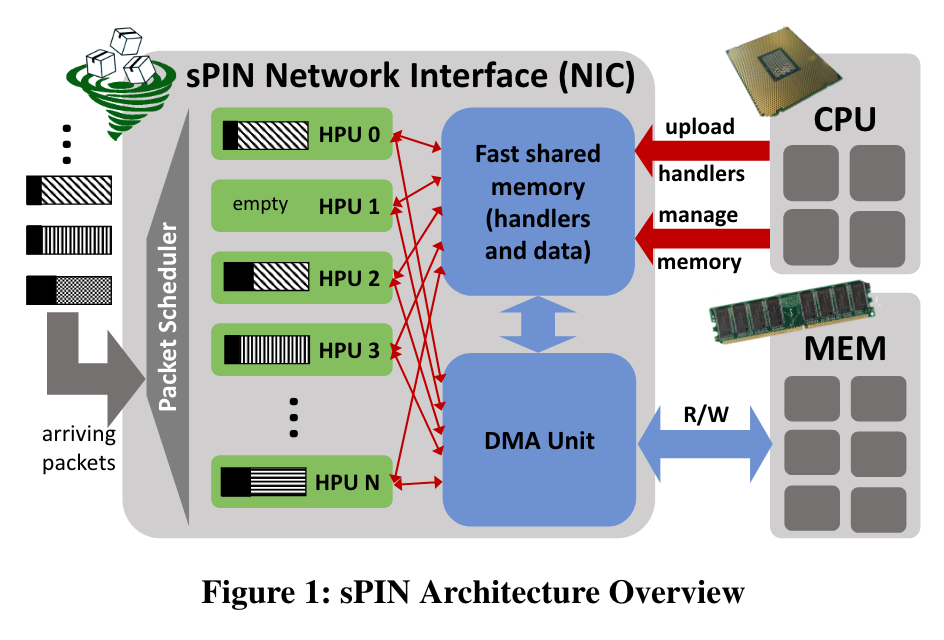
其中,收到的数据包首先存储到Fast shared memory中,被Scheduler分发到HPU上进行处理,在必要时才通过DMA访问Host主存。
此外,文中还有个小细节提到,HPU可以实现为GPU类似的硬件上下文架构,原文如下:
HPUs can be implemented using massive multithreading to utilize the execution units most efficiently. For example, if handler threads wait for DMA accesses, they could be descheduled to make room for different threads. Only the context would need to be stored, similarly to GPU architectures.
然后,在HPU上,采用了如下编程模型,分别为一个Channel中的Packet的Header、Payload、Completition提供了Handler:

Simulation & Result
作者使用了LogGOPSim和gem5。参数上大家可以自行参考原文。大致结果如下:
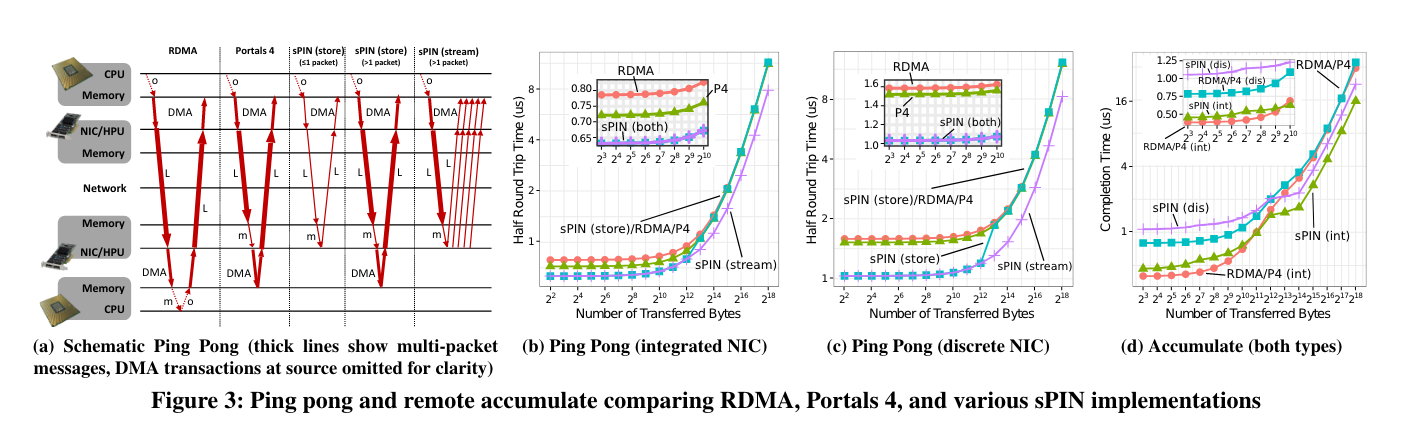
Use Case
作者提到了一下场景的Use Case:
- Asynchronous Message Matching
- MPI
- Distributed RAID Storage