Background As DRAM prices continue to rise, many users are exploring alternative solutions to manage memory more efficiently….

惊人的 IOMMU Overhead 与不合理的 AQC 网卡驱动
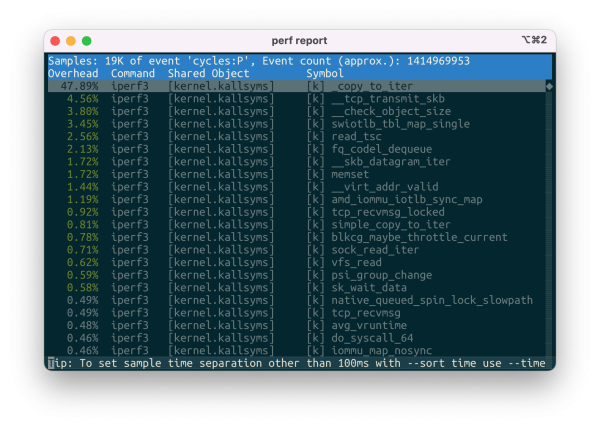
背景 给家里的 AMD AI MAX 395 小主机加了个 Thunderbolt 万兆网卡,期望给这台小主机通上 10Gbps 的信息高速公路,这样我可以利用家里的 NAS 的大容量存储快速拉 LLM ,网卡用的是几年前买给 Mac 用的 QNAP…
让树莓派4 WireGuard 性能从 400Mbps 飞涨到 1Gbps
背景 由于学校机房依然需要网络认证,因此我采用了使用 WireGuard 从别处接入网络的方式。为了评估放在学校机房的软路由需要什么样的性能才足够跑满千兆大包 WireGuard ,上周末写了个 WireGuard Benchmark 脚本 来评估 CPU 以及 Kernel 网络栈处理 WireGuard 的性能。为了方便评估以取得更多的结果,我采用 network namspace…
第一次给Kernel邮件列表交Patch遇到的小坑
第一次交 PATCH ,交成了这样: 而我交 patch 的方式只不过是: git format-patch 457391b0380335d5e9a5babdec90ac53928b23b4 –cover-letter # edit cover letter git send-email \ –from…
让Thunderbolt可以使用更大的BAR
问题描述 在Xilinx 7-Series FPGA上用AXI Memory Mapped to PCI Express IP核设置了一个256M的BAR,这个BAR直接连接到主板的PCIe上可以正常进行MMIO,但将FPGA通过Thunderbolt硬盘盒+M.2转PCIe连接到Thunderbolt上却无法使用。 通过查阅dmesg可观测到如下报错信息: [ 246.677146] pci 0000:0c:00.0: BAR 0: no…
Draco(MICRO’20) Architectural and Operating System Support for System Call Security 阅读笔记
要解决的问题 Linux内核提供了seccomp来对syscall权限进行检查,被广泛应用在容器、沙盒等多种场景,例如Docker和Android。但原版seccomp的实现是通过BPF对定义的规则一条条进行检查,如下图所示,十分低效: 同时,作者也进行了一系列的benchmark发现这样的检查带来了较大的开销: 其中,左边的docker-default指的是Docker默认使用的seccomp-profile,syscall-noargs指的是使application-specific profile但只检查syscall id而不检查参数,而syscall-complete就在noargs的基础上加上参数检查,最后加上-2x的后缀表示的是这些检查复制2次,来建模更复杂的安全检查场景。 可以看出,seccomp检查带来的开销即使是对于像nginx这样的macro-benchmarks也是比较大的,但现有的seccomp使用BPF,规则十分灵活,因此需要针对这种灵活的规则设计一种加速的方法。 Observation 检查系统调用ID会给Docker容器中的应用带来明显(noticeable)的性能开销。 检查系统调用参数比只检查系统调用ID的开销大得多(significantly more expensive)。 规则加倍,开销加倍。 syscall with 相同id和参数存在局部性(下图指明了实验中的距离) 解决方法 为了解决这个问题,作者引入了一个Fast…
在Xilinx FPGA上搭建SoC
背景 之前出于科研需求和龙芯杯比赛需求都自己搭建过SoC来运行CPU软核,整理一下我的搭建SoC的流程。以下的讨论基于MIPS和RISC-V两种软核ISA为例。 大家也可以参考我搭建的两个SoC以及对应的软件: cyysoc (RISC-V Rocket+Coherent DMA) pblaze_soc 某大船SSD上的xc7k325t-2 FPGA+2G 72bit DDR3 ECC 用了某个PCI-E引出到SFP接口的扩展板,连接光模块/电口模块提供网络 PCI-E和SFP的IO在FPGA上都是GTX 用了某个该板子的IO接口转USB UART的扩展板 扩展板上面还有rgmii…
调试sfence.vma,12天之差错过Linux Patch一个
起因 最近造了个RISC-V CPU模拟器——CEMU,并实现了软件模拟TLB来加速地址翻译。而TLB和页表并不自带一致性,在RISC-V上需使用sfence.vma这样的指令来刷掉TLB和Page Table Cache(如果存在)和硬件流水线上的指令来确保页表修改生效。并通过了RISC-V Test中的所有测试,然而在启动Linux进入Busybox却遇到如下问题: 尽管Busybox能跑起来并正常使用,但同样的内核在qemu和Rocket上都是完全正常的,因此我继续探索了一下可能的问题。后来objdump了一下busybox的这个地址,发现是一条ret(jalr)指令,而跳转的地址是从栈上ld的。 因此我就怀疑是页表出现了问题导致fork的时候这个进程的栈对别的进程的栈产生了破坏。 第一次尝试 我首先怀疑了TLB查找出现问题,因此我修改了sfence.vma指令的实现,将sfence.vma实现为不管asid和va,全刷TLB,结果用户进程正常载入了。 后续继续做了些尝试,发现只要在执行sfence.vma的时候忽略ASID,但保留va的判断,用户进程依然正常运行。 第二次尝试 这次在实验室里twd2和dram一起来看我调试了。我在每次TLB Hit的情况下都重新进行一遍Page Table Walk,并检查Walk出来的PTE结果和TLB的区别。 结果发现Linux Kernel在一个Hart启动的时候会出现一次页表的W位不同的问题,但那是一条sfence.vma指令的fetch,所以没有对运行结果产生影响。…
U-Boot RISC-V M Mode的灵车SMP启动
为了方便运行任意M Mode软件,同时不想自制Bootloader。我决定在我的RISC-V SoC上使用M Mode U-Boot。然后再上面跑OpenSBI再把Linux作为OpenSBI的Payload运行。但U-Boot的go命令只会修改当前Hart的PC,并不会让其他Hart进行跳转。这就导致后续OpenSBI启动Linux一发送IPI就不断进入Trap Handler。 最后我想了个简单解决方法是,一旦进入Trap Handler且发现是当前无法解决的Trap就跳转到DRAM_BASE(也就是OpenSBI的TEXT段开始地址),并将a0寄存器设置上hartid(符合OpenSBI要求)。这样当IPI产生时其他核就会进入OpenSBI。配合Rocket Chip开双核,经过多次测试,Linux SMP均正常工作。不过比较灵车,理论上正确做法应该修改U-Boot代码控制其他核的IPI跳转。 修改在此:https://github.com/cyyself/u-boot/commit/c637a978068c434691899f1139b8b3e6c45efc93 在这种方法下,只需要保证设备树科学,然后使用u-boot通过tftp/串口将OpenSBI编译的fw_payload.bin载入到DRAM_BASE,然后使用go 0x80000000即可完成SMP启动。不过这种灵车做法需要确保的是,启动过程发送IPI之前不会对U-Boot使用的内存地址进行任何破坏。
Back to Top