调试sfence.vma,12天之差错过Linux Patch一个
起因
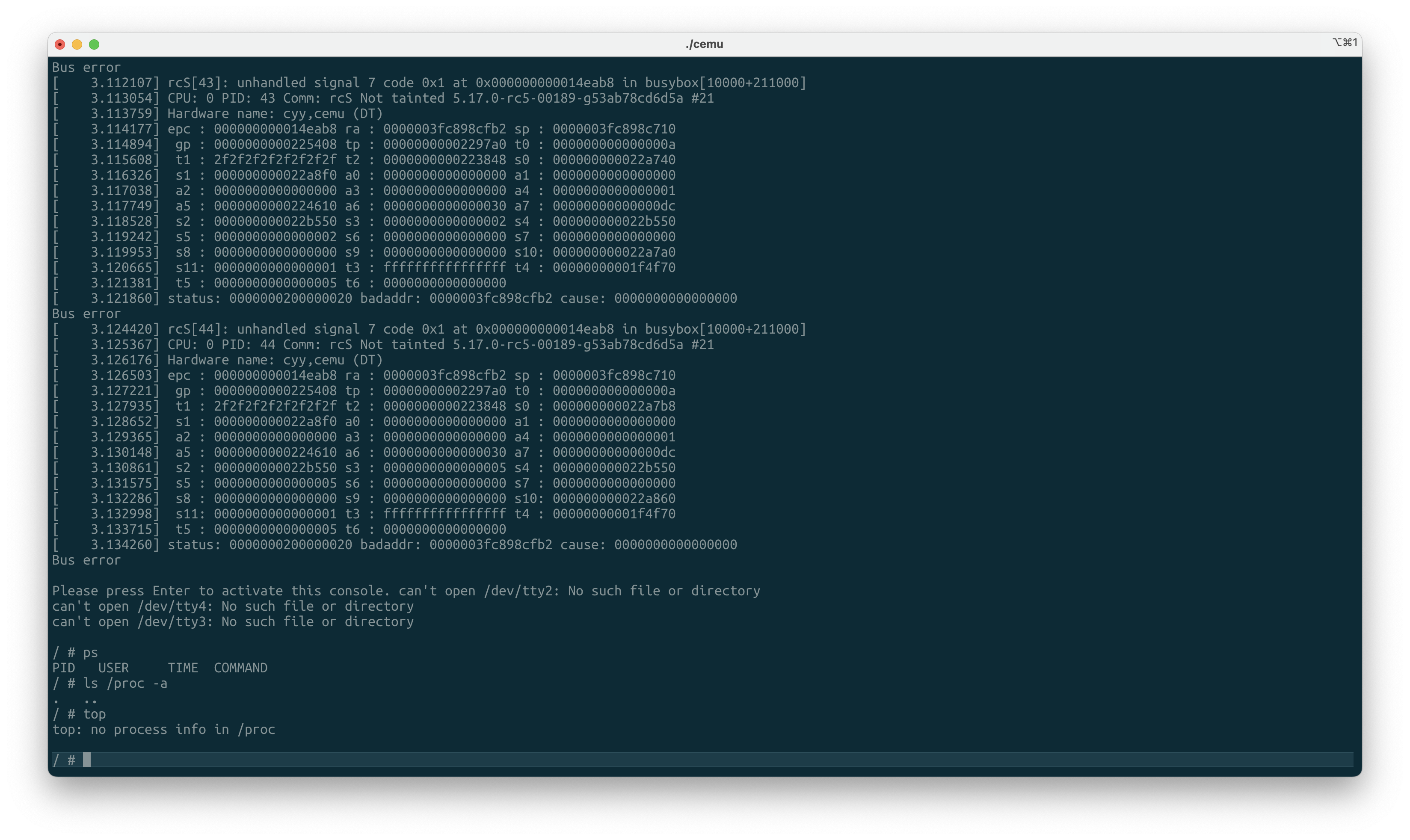
最近造了个RISC-V CPU模拟器——CEMU,并实现了软件模拟TLB来加速地址翻译。而TLB和页表并不自带一致性,在RISC-V上需使用sfence.vma这样的指令来刷掉TLB和Page Table Cache(如果存在)和硬件流水线上的指令来确保页表修改生效。并通过了RISC-V Test中的所有测试,然而在启动Linux进入Busybox却遇到如下问题:

尽管Busybox能跑起来并正常使用,但同样的内核在qemu和Rocket上都是完全正常的,因此我继续探索了一下可能的问题。后来objdump了一下busybox的这个地址,发现是一条ret(jalr)指令,而跳转的地址是从栈上ld的。
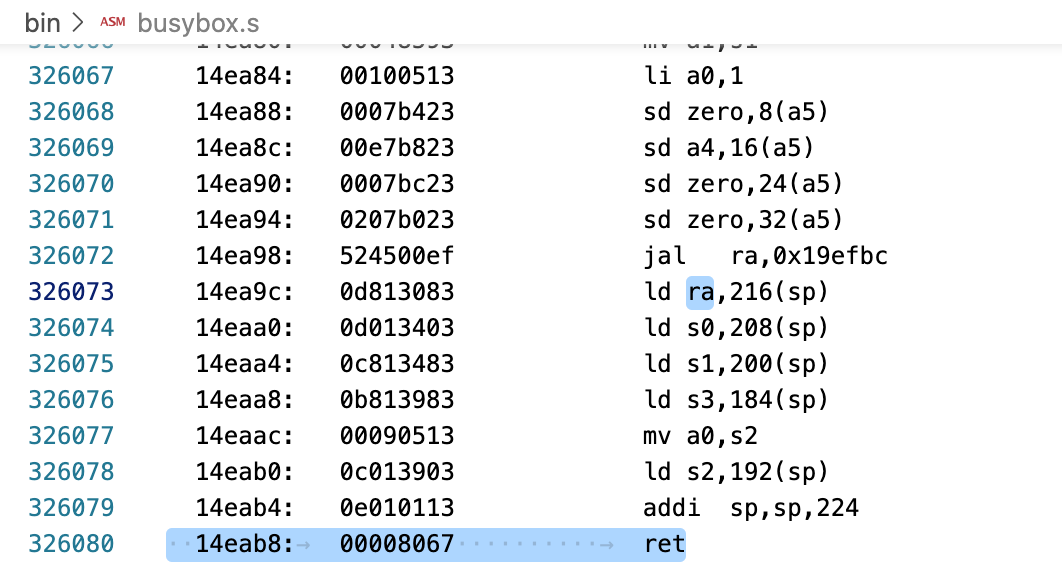
因此我就怀疑是页表出现了问题导致fork的时候这个进程的栈对别的进程的栈产生了破坏。
第一次尝试
我首先怀疑了TLB查找出现问题,因此我修改了sfence.vma指令的实现,将sfence.vma实现为不管asid和va,全刷TLB,结果用户进程正常载入了。
后续继续做了些尝试,发现只要在执行sfence.vma的时候忽略ASID,但保留va的判断,用户进程依然正常运行。
第二次尝试
这次在实验室里twd2和dram一起来看我调试了。我在每次TLB Hit的情况下都重新进行一遍Page Table Walk,并检查Walk出来的PTE结果和TLB的区别。
结果发现Linux Kernel在一个Hart启动的时候会出现一次页表的W位不同的问题,但那是一条sfence.vma指令的fetch,所以没有对运行结果产生影响。


但是继续运行发现,在/sbin/init开始运行后,出现了大量PTE的W位TLB和页表不匹配的情况,这就导致Busybox在fork时的COW页面可能没有正确清除W位使其能够在写入是trap到内核进行页面的复制,造成一个进程写了另一个fork进程的栈,这就导致了前文所述的现象问题。
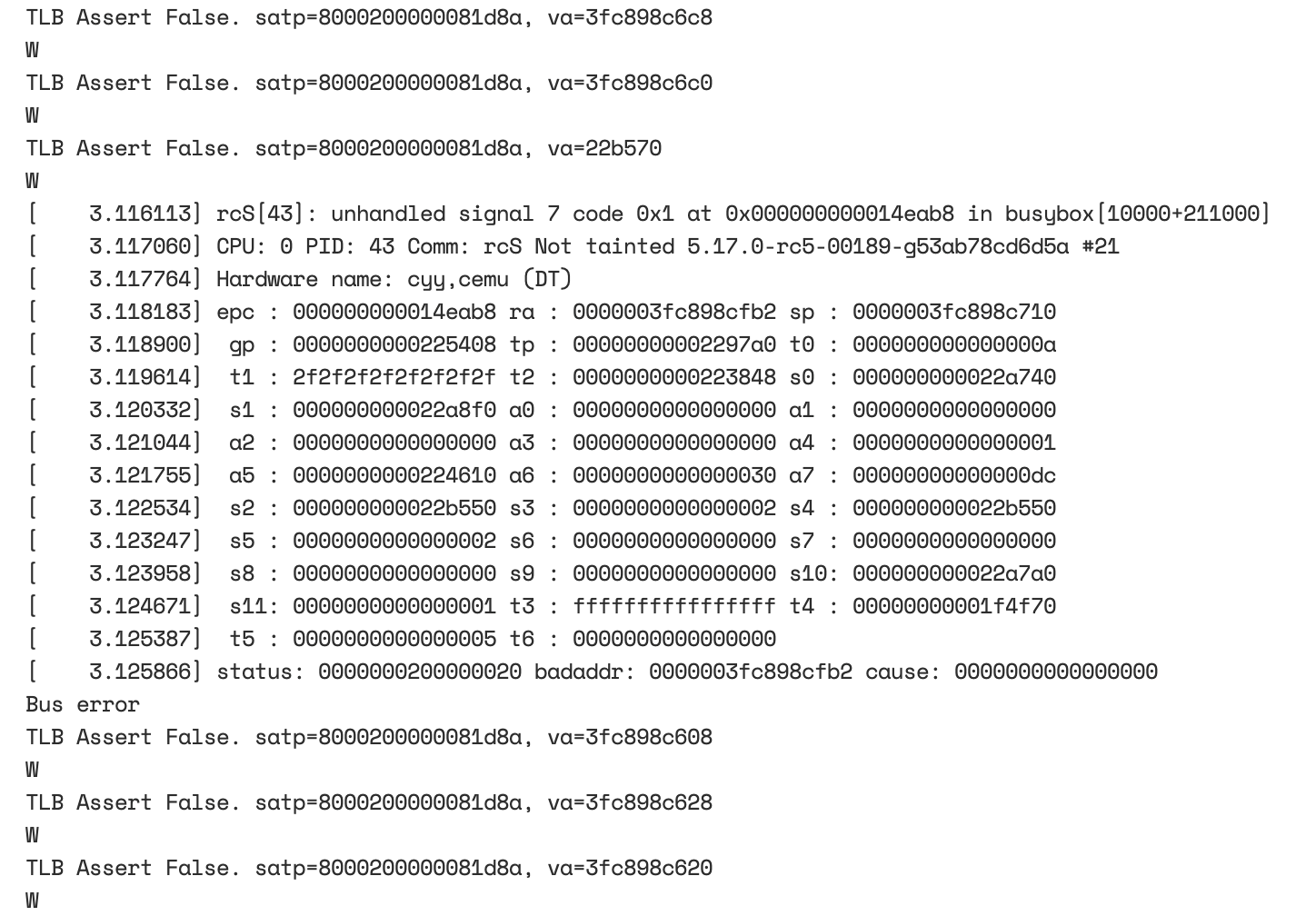
第三次尝试
这次在sfence.vma的时候输出了(hart_id,asid,va),同时在检测到TLB和PTW结果不匹配的时候输出了错误的asid,并让TLB自动更新到最新PTW的结果,结果如下(注:所有数采用16进制输出):

这里可以看出,执行sfence.vma使用了asid=0x10008,而错误的TLB Entry的ASID=8。
这时候重新翻看了RISC-V Spec,发现sfence.vma指令执行时应该忽略rs2(传入asid寄存器)的超过硬件asid高位的部分。同时软件也不应该将高位放在寄存器中。
我看到这句话后,修复了模拟器的sfence.vma实现,将传入的asid &=0xffff问题解决。
Linux代码分析
尽管至此问题已经解决,但根据RISC-V的Spec,Linux在使用sfence.vma指令的时候也不应该在ASID处填充高位,毕竟RISC-V Spec是这么写的:

因此,我们三个人就开始研究Linux代码为什么会存在这个问题没有被发现,以及研究了为什么qemu和spike模拟器没能跑出来。结果是qemu上的sfence.vma没有管asid和va实现为全刷,而spike代码搜索asid似乎只在计算satp的函数中找到。然后我们继续研究Linux代码,可能还能顺便给Linux交个Patch。
于是我们开始研究Linux的代码,定位到了执行sfence.vma的函数,位于arch/riscv/mm/tlbflush.c,如下:
static void __sbi_tlb_flush_range(struct mm_struct *mm, unsigned long start,
unsigned long size, unsigned long stride)
{
struct cpumask *cmask = mm_cpumask(mm);
unsigned int cpuid;
bool broadcast;
if (cpumask_empty(cmask))
return;
cpuid = get_cpu();
/* check if the tlbflush needs to be sent to other CPUs */
broadcast = cpumask_any_but(cmask, cpuid) < nr_cpu_ids;
if (static_branch_unlikely(&use_asid_allocator)) {
unsigned long asid = atomic_long_read(&mm->context.id);
if (broadcast) {
sbi_remote_sfence_vma_asid(cmask, start, size, asid);
} else if (size <= stride) {
local_flush_tlb_page_asid(start, asid);
} else {
local_flush_tlb_all_asid(asid);
}
} else {
if (broadcast) {
sbi_remote_sfence_vma(cmask, start, size);
} else if (size <= stride) {
local_flush_tlb_page(start);
} else {
local_flush_tlb_all();
}
}
put_cpu();
}这里我们可以发现,用于刷新的asid是直接使用的mm_struct中的context.id。
接着,就是寻找context.id是在哪被设置了,最后通过搜索发现是在arch/riscv/mm/context.c中,代码如下:
static void set_mm_asid(struct mm_struct *mm, unsigned int cpu)
{
unsigned long flags;
bool need_flush_tlb = false;
unsigned long cntx, old_active_cntx;
cntx = atomic_long_read(&mm->context.id);
/*
* If our active_context is non-zero and the context matches the
* current_version, then we update the active_context entry with a
* relaxed cmpxchg.
*
* Following is how we handle racing with a concurrent rollover:
*
* - We get a zero back from the cmpxchg and end up waiting on the
* lock. Taking the lock synchronises with the rollover and so
* we are forced to see the updated verion.
*
* - We get a valid context back from the cmpxchg then we continue
* using old ASID because __flush_context() would have marked ASID
* of active_context as used and next context switch we will
* allocate new context.
*/
old_active_cntx = atomic_long_read(&per_cpu(active_context, cpu));
if (old_active_cntx &&
((cntx & ~asid_mask) == atomic_long_read(¤t_version)) &&
atomic_long_cmpxchg_relaxed(&per_cpu(active_context, cpu),
old_active_cntx, cntx))
goto switch_mm_fast;
raw_spin_lock_irqsave(&context_lock, flags);
/* Check that our ASID belongs to the current_version. */
cntx = atomic_long_read(&mm->context.id);
if ((cntx & ~asid_mask) != atomic_long_read(¤t_version)) {
cntx = __new_context(mm);
atomic_long_set(&mm->context.id, cntx);
}
if (cpumask_test_and_clear_cpu(cpu, &context_tlb_flush_pending))
need_flush_tlb = true;
atomic_long_set(&per_cpu(active_context, cpu), cntx);
raw_spin_unlock_irqrestore(&context_lock, flags);
switch_mm_fast:
csr_write(CSR_SATP, virt_to_pfn(mm->pgd) |
((cntx & asid_mask) << SATP_ASID_SHIFT) |
satp_mode);
if (need_flush_tlb)
local_flush_tlb_all();
}这里我们可以发现,Linux使用了context.id的高位作为version。用于检测ASID溢出后的复位问题(避免TLB Reuse Attack破坏页表权限控制以及程序执行错误)。然而在前面的调用sfence.vma的地方,却没有将它bitwise-and上asid_mask。
我们都非常兴奋,然后打开了RISC-V邮件列表,搜索ASID,一看:
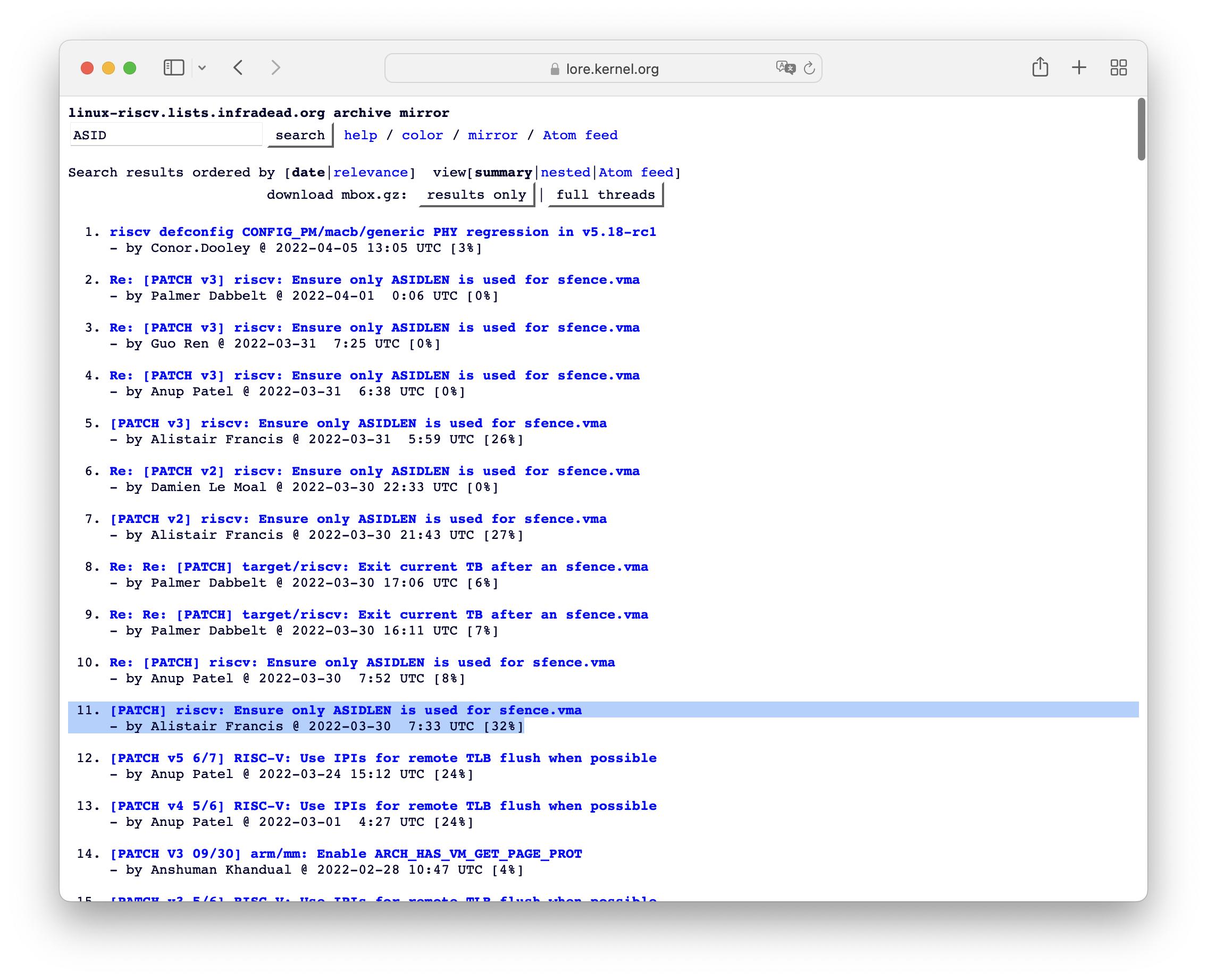
同样的Bug已经在12天前被发现了。
错过了一个让全世界RISC-V设备运行我的Patch代码的宝贵机会。
而观察了一下交这个Patch的人,发现是在西数研究安全的同行,最近还在做QEMU,可能也是和我一样实现了一个错误的模拟器发现Linux出了问题才发现这一点吧,毕竟这个Bug要能产生问题需要满足硬件和软件(Linux)都没按照Spec要求。
后续实验-ASID大小核
我在我的CEMU模拟器上实验了一下ASID大小核,结果果然不出我所料:
diff --git a/src/core/riscv/rv_priv.hpp b/src/core/riscv/rv_priv.hpp
index fa0e423..9efa8d8 100644
--- a/src/core/riscv/rv_priv.hpp
+++ b/src/core/riscv/rv_priv.hpp
@@ -318,6 +318,7 @@ public:
if (cur_priv == S_MODE && mstatus->tvm) return false;
satp_def *satp_reg = (satp_def*)&csr_data;
if (satp_reg->mode !=0 && satp_reg->mode != 8) satp_reg->mode = 0;
+ satp_reg->asid = satp_reg->asid & (hart_id ? 0xffff : 0xff);
satp = csr_data;
break;
}
@@ -555,7 +556,7 @@ public:
bool sfence_vma(uint64_t vaddr, uint64_t asid) {
const csr_mstatus_def *mstatus = (csr_mstatus_def*)&status;
if (cur_priv < S_MODE || (cur_priv == S_MODE && mstatus->tvm)) return false;
- sv39.sfence_vma(vaddr,asid);
+ sv39.sfence_vma(vaddr,asid & (hart_id ? 0xffff : 0xff));
return true;
}
void raise_trap(csr_cause_def cause, uint64_t tval = 0) {