Background 最近仔细学习了一下 TileLink 以及 TL-C 的一致性协议,希望写一篇文章给 有AMBA AXI基础 的读者提供一篇 TileLink 快速入门的介绍。 本文参考的 TileLink Spec 基于https://starfivetech.com/uploads/tilelink_spec_1.8.1.pdf Variant Protocol Narrow…
Intel Data Dependent Prefetcher 对 SPEC CPU 2017 的影响
背景 最近在做一些商业硬件的 Data Dependent Prefetcher 测量,无意中注意到 Intel 13 代酷睿是有 Data Dependent Prefetcher 的,因此先进行了一个简单的尝试。 介绍与开关控制 介绍可以参考 Intel的文档 。 而根据…
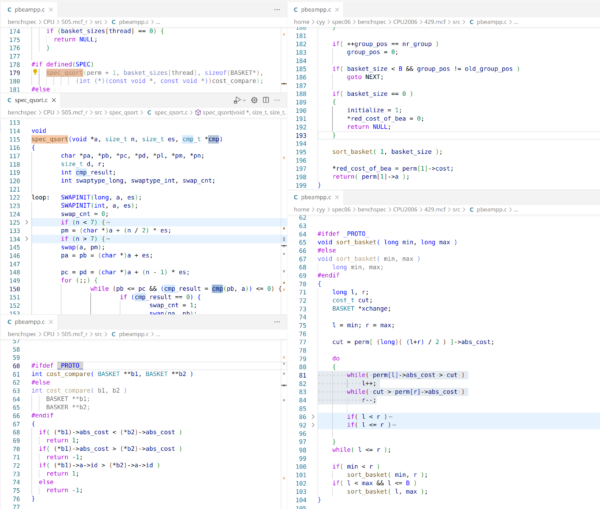
SPEC CPU 2017 mcf 与 2006 的差异浅析
背景 最近朋友 Easton Man 告诉了我一些SPEC CPU 2006 与 2017 的一些性能计数器 Topdown 统计结果,在观测他的结果后我惊讶地发现,SPEC CPU 2017中 mcf 这一 workload 对…
尝试Xilinx FPGA上的BUFGCE
最近在学习 Firesim ,其中对我自己科研很重要的一个功能便是 FASED 提供了 Memory Timing Model 的模拟。因为之前和别人合作论文曾被审稿人提出过 100MHz FPGA 使用 1600MHz 的内存,使得内存的延迟非常低,其性能表现像是一个大的 LLC Cache 而不是真实的内存,导致访存性能与真实 ASIC…
浅谈早期 Fault Tolerance 虚拟机原理
背景 最近遇到了一些灵车硬件损坏问题,包括自己的台式机 13900K CPU 突然死机后重启就出现 CPU soft lockup,再重启直接无法点亮;自己的旧台式机出现 Correctable ECC 报错(感谢AMD消费级CPU也部分支持ECC);以及一台别人的服务器上解压tar.gz包出现了CRC错误。一周内的这些经历使我开始思考云计算场景如何Tolerance这些奇怪的硬件损坏问题,于是看到了一篇VMWare vSphere 4(2010)年代的论文——The Design of a Practical System…
DDR4与HBM在UltraScale+ HBM上的IOPS测试
最近一个科研 idea 需要 measure 一些内存器件的 latency 数据,因此用 FPGA 对主流的内存器件的访问 Latency 进行了一个调研,诚然这样的结果和 FPGA 上具体 Memory Controller 的 IP 实现有关,但也可以作为一个参考,相信…
Augury: Using Data Memory-Dependent Prefetchers to Leak Data at Rest 阅读笔记
概述 这是一篇发表在 Oakland’22 ( aka IEEE S&P ) 的文章,讲的是在 Apple M1 上发现了前所未有的 Data Memory-Dependent Prefetcher (下称 DMP ),该预取器也带来了前所未有的侧信道攻击。作者对…
sPIN: High-performance streaming Processing in the Network 阅读笔记
这是一篇来自 SCPL@ETHZ 组在 SC’17 上的一篇文章。主要想法是在 RDMA 网卡上加入一个处理器用来 Offloading 一部分数据移动任务,并在 LogGOPSim 与 gem5 上进行了实验。 原文链接 Motivation 当前高能效处理器组成的高度可扩展的系统发展带来了总线互联的压力。例如在 400Gbps 的网络中,一个…
Draco(MICRO’20) Architectural and Operating System Support for System Call Security 阅读笔记
要解决的问题 Linux内核提供了seccomp来对syscall权限进行检查,被广泛应用在容器、沙盒等多种场景,例如Docker和Android。但原版seccomp的实现是通过BPF对定义的规则一条条进行检查,如下图所示,十分低效: 同时,作者也进行了一系列的benchmark发现这样的检查带来了较大的开销: 其中,左边的docker-default指的是Docker默认使用的seccomp-profile,syscall-noargs指的是使application-specific profile但只检查syscall id而不检查参数,而syscall-complete就在noargs的基础上加上参数检查,最后加上-2x的后缀表示的是这些检查复制2次,来建模更复杂的安全检查场景。 可以看出,seccomp检查带来的开销即使是对于像nginx这样的macro-benchmarks也是比较大的,但现有的seccomp使用BPF,规则十分灵活,因此需要针对这种灵活的规则设计一种加速的方法。 Observation 检查系统调用ID会给Docker容器中的应用带来明显(noticeable)的性能开销。 检查系统调用参数比只检查系统调用ID的开销大得多(significantly more expensive)。 规则加倍,开销加倍。 syscall with 相同id和参数存在局部性(下图指明了实验中的距离) 解决方法 为了解决这个问题,作者引入了一个Fast…
Back to Top