Augury: Using Data Memory-Dependent Prefetchers to Leak Data at Rest 阅读笔记
概述
这是一篇发表在 Oakland’22 ( aka IEEE S&P ) 的文章,讲的是在 Apple M1 上发现了前所未有的 Data Memory-Dependent Prefetcher (下称 DMP ),该预取器也带来了前所未有的侧信道攻击。作者对 DMP 以及可能的攻击进行了介绍,并在 M1 上进行了相关实验,展示了 M1 上 DMP 的运行条件,预取的范围等,并对如何缓解进行了展示。
什么是DMP
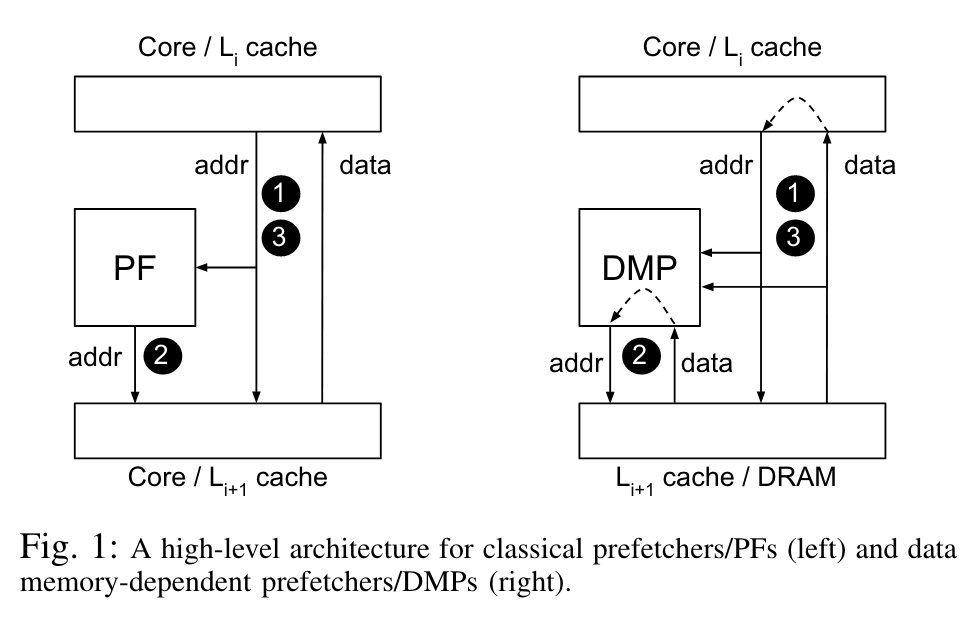
作者先用一张图阐明了传统预取器与 DMP 的区别。传统预取器只考虑地址以及后续地址的关联来进行预测,对预取到的 data 并不 care ,这就使得一些场景,例如 pointer-chasing 并不能很好地处理。而 DMP 在进行预测时也将过去取到的 data 纳入考虑,这就可以通过一定的方式对data中的指针进行识别。
对于 DMP 而言,一个十分有用的场景可以是访问一个 array of pointers ,预取器可以从这个 array 中得到要预取的地址,从而先预取,而不必等待 CPU 流水线拿到指针所指的地址后,再一步步把地址发给 LSU 再发给 Cache ,从而大幅加快这种情况的访问速度。
而作者提到,尽管过去已经相关工作指出 DMP 潜在的侧信道,但在 Apple M1 之前,没有商业级处理器实现这个功能,作者测试了当时所有的 Intel 和 AMD 的处理器,均无发现这种加速的现象。
DMP有哪些安全问题
我想这个问题熟悉 Meltdown/Spectre 的同学知道 DMP 的存在已经能想到无数种攻击了,这里我们简单举一个 out of bound read 的例子,关于其它的攻击大家感兴趣可以阅读原文。
int *aop[SIZE]; // array of pointers
int *input = user_choice(p1,p2,p3); // 用户输入会导致input变为p1,p2,p3中的一个
// 假定*input的地址紧接在*arr其后,因此对arr进行prefetch时,由于处理器DMP不知道arr的范围,input也会当做arr的部分一并预取
thrash_cache(); // 避免*p1,*p2,*p3已经在cache中,导致影响。
*aop[0];
*aop[1];
// ....
*aop[SIZE-1];
// 循环展开读取arr,循环展开目的是为了避免分支预测带来的影响,同时只需要诱导一种流式访问*arr[i]的pattern即可
measure_time(*p1);
measure_time(*p2);
measure_time(*p3);
// 测量访问*p1,*p2,*p3的时间,从而观测出哪一个被预取成功,进而推出*input的值。Apple M1上的测量结果
作者总结了一张图:
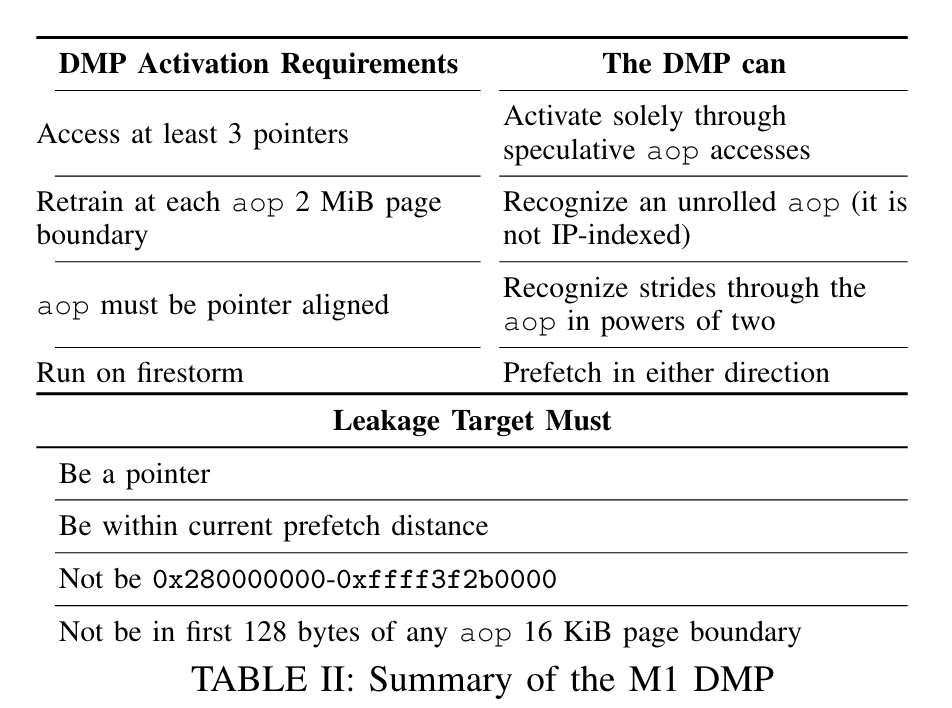
其中,我个人还想补充的一个细节是,作者在文中提到DMP是会进行地址翻译包括Page Table Walk的,我个人想到这样或许会存在页表Access Bit的侧信道,文中并没有指出这样的预取是否会写页表的Access Bit。
然后我去翻了下我熟悉的RISC-V ISA手册,它允许uarch将access bit的设置实现为必须exact访问或是预测执行就写。实际上这两种做法是性能和安全可以争论的问题。(但如果像InvisiSpec类似的做法牺牲一点点芯片面积,搞一个speculative TLB呢?)
此外,我个人还比较关注表中的另一点是它允许预取的 虚拟 地址范围。这一点我觉得需要详细说明,在macOS中,0x7fe840004000是用户进程可以map的虚拟地址最大值,作者这个值是通过asahilinux测得的。而对于这个奇怪的0x280000000,作者表示没有任何头绪。
侧信道缓解
类似Meltdown/Spectre提到的Removing secrets from virtual address space外,作者还提到可以限制数据被当做指针以及避免DMP识别到指针(回想之前作者表格里说了必须是8B aligned指针才能被识别)。
但我觉得强行让指针不对齐是一个不太可取的做法,很多测试都说明了现代处理器对于不同类型的unaligned load/store是有一定开销的,更别提部分处理器会将unaligned load / store直接trap到kernel/monitor,我们无法预知未来的处理器上这个开销会有多大,因此我个人认为不是一个很可取的设计。也让我想起来之前帮朋友猜测的一个Rocket上Zk扩展打不赢C实现的一个奇怪现象的原因,最后交了patch。