
Chisel编译时间优化实例——将香山的双核RTL生成时间从36分钟压缩到7分钟
背景
自从香山新后端合并后, Chisel 编译时间大幅增加,特别是在双核的 DefaultConfig 下,在我的 13900K 机器 + OpenJDK 11 的条件下, FIR 的生成时间已经达到的 34 分钟,具体可以见该 issue ,而在之前, FIR 生成时间仅为 2 分钟不到。这样的编译时间大幅增加导致开发流程不再敏捷,大幅时间浪费在等待编译上。
观察
我首先怀疑是电路规模也存在大幅增加,因此我首先观测了 FIR 的大小。通过 git checkout 或 git reset --hard 使用新后端合并前的 commit 进行观察可发现,在使用 DefaultConfig 双核的情况下,旧后端的 FIR 大小为 1.4GB ,新后端为 2.4GB 。尽管 FIR 大小不能完全反映电路大小,但时间并不应该是小于 2 分钟至 34 分钟的区别。
因此,我怀疑问题出在以下两点:
- Scala 的写法不同导致了 CPU 微架构层面出现了巨大的 IPC 差异
- 存在大量重复的代码执行,而 RTL 的生成过程中存在非常多可以复用的部分
Profiling
鉴于 Scala 最终也会在 JVM 里执行,我首先调研了一些 Java 的 Profiling 工具,最后发现我们常用的 IDEA idea 自带该功能。使用方法非常简单:
在打开的Profile窗口后,去终端执行编译(例如 make verilog NUM_CORES=2 MFC=1),此时建议设置IDEA布局将终端放在Profiler右边,时刻观测状态。
此时可在Profiler窗口中观察到Mill执行编译的Java进程。
等待Scala编译完成后,可在Profiler窗口中观测到进程名变为TopMain,此时我们点击右键来Attach。
然后等待编译执行完成,观察结果:
(注,第一次使用时可能遇到Java的-Xmx不足导致进程崩溃的问题,但Profiler阶段不影响,如果遇到idea进程退出依然可以在~/IdeaSnapshots/中观测到Profiling结果)
在此我们可以观察大量的信息:
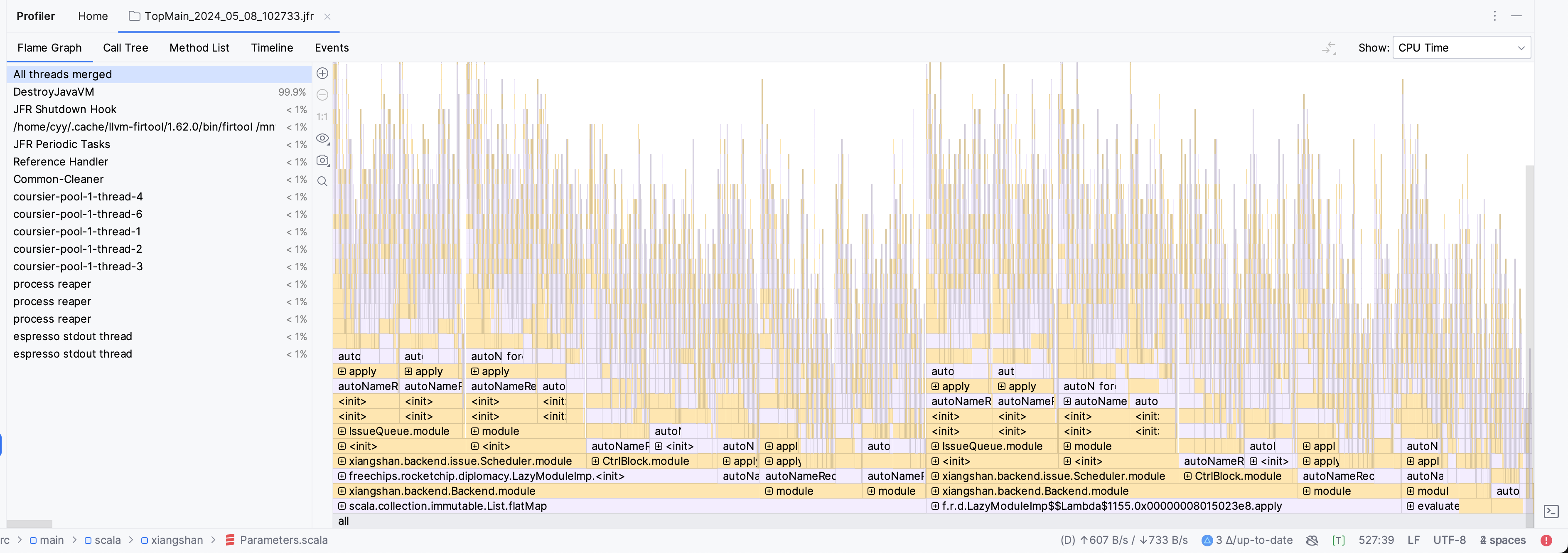
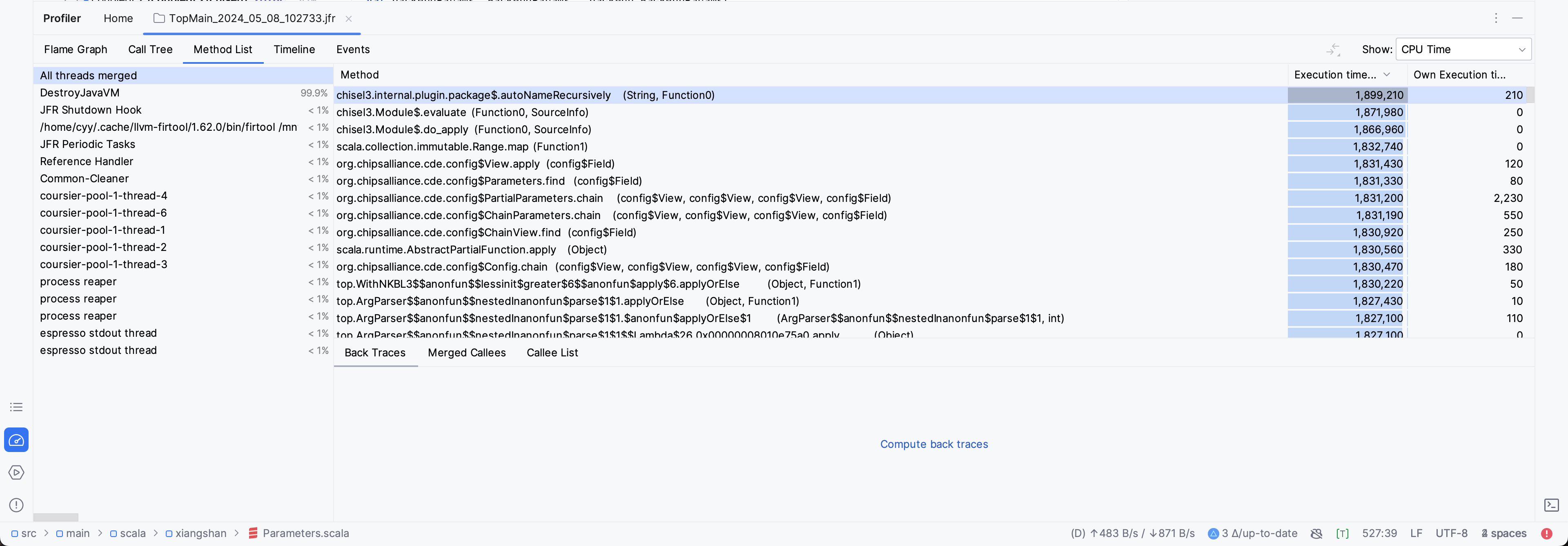
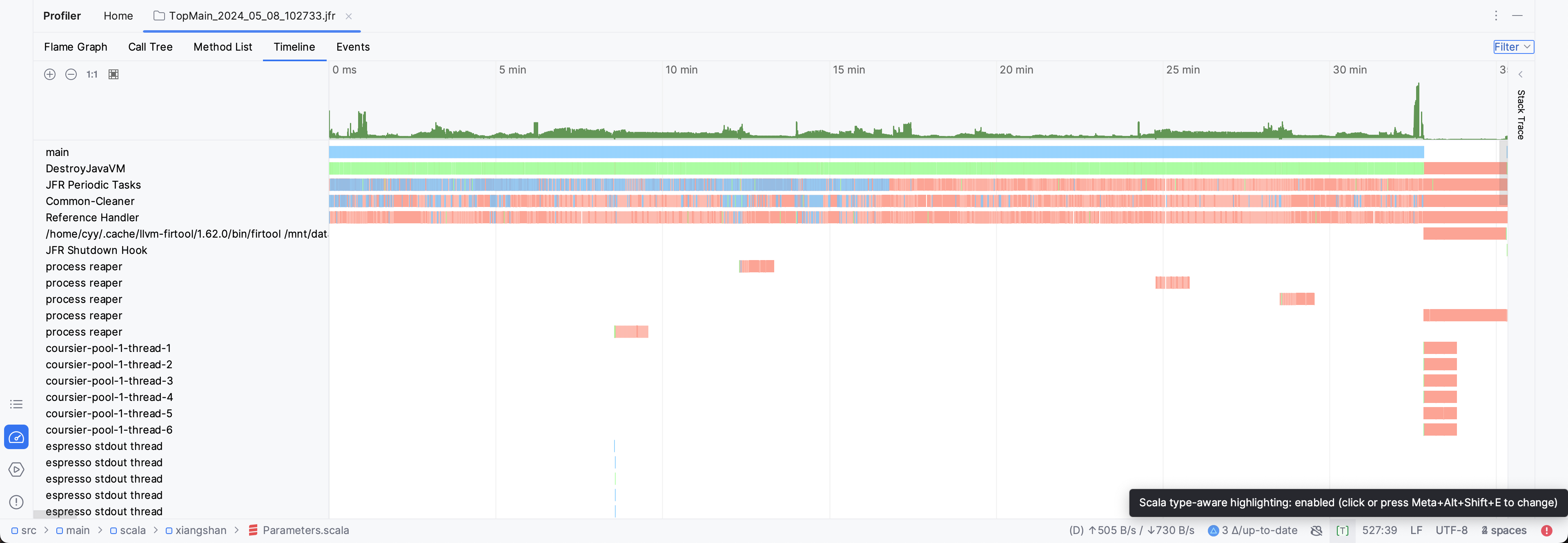
对比采样结果
旧后端:
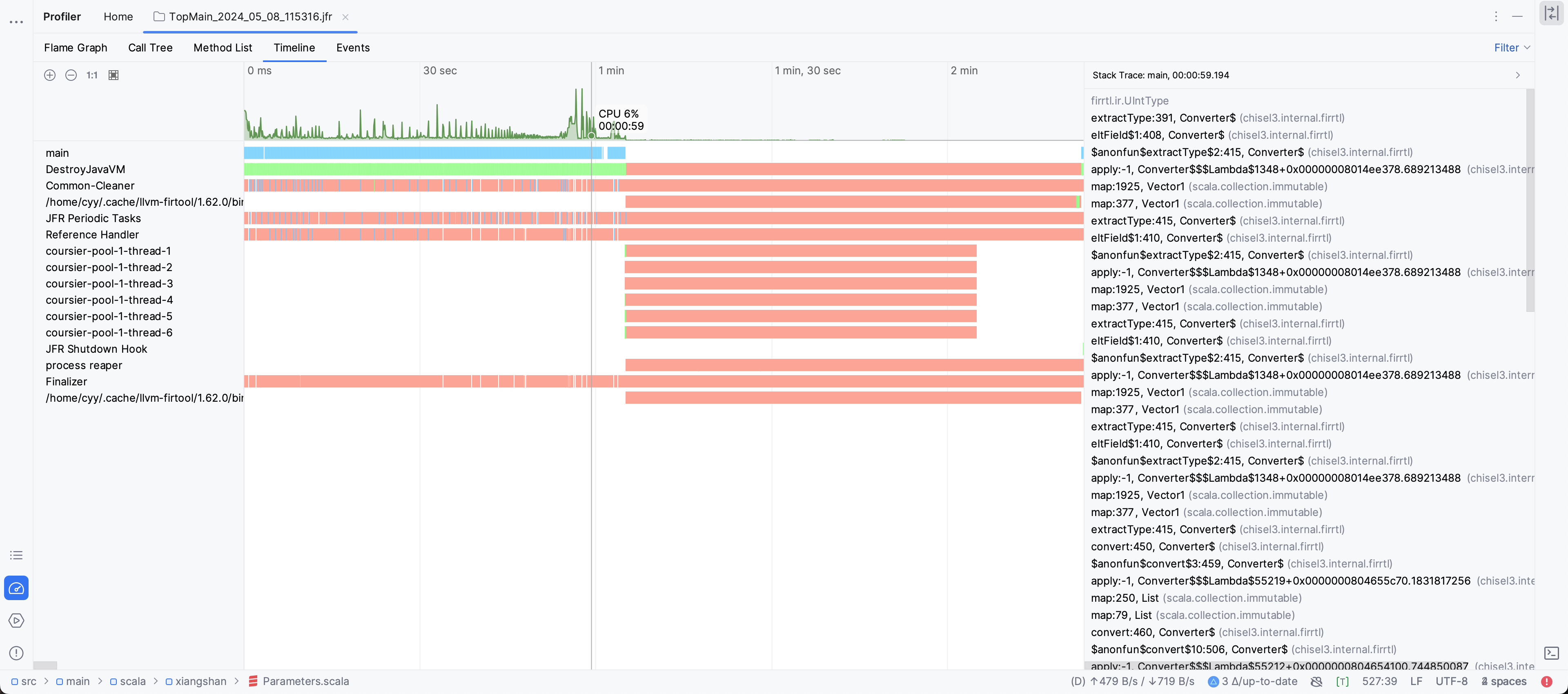
新后端:
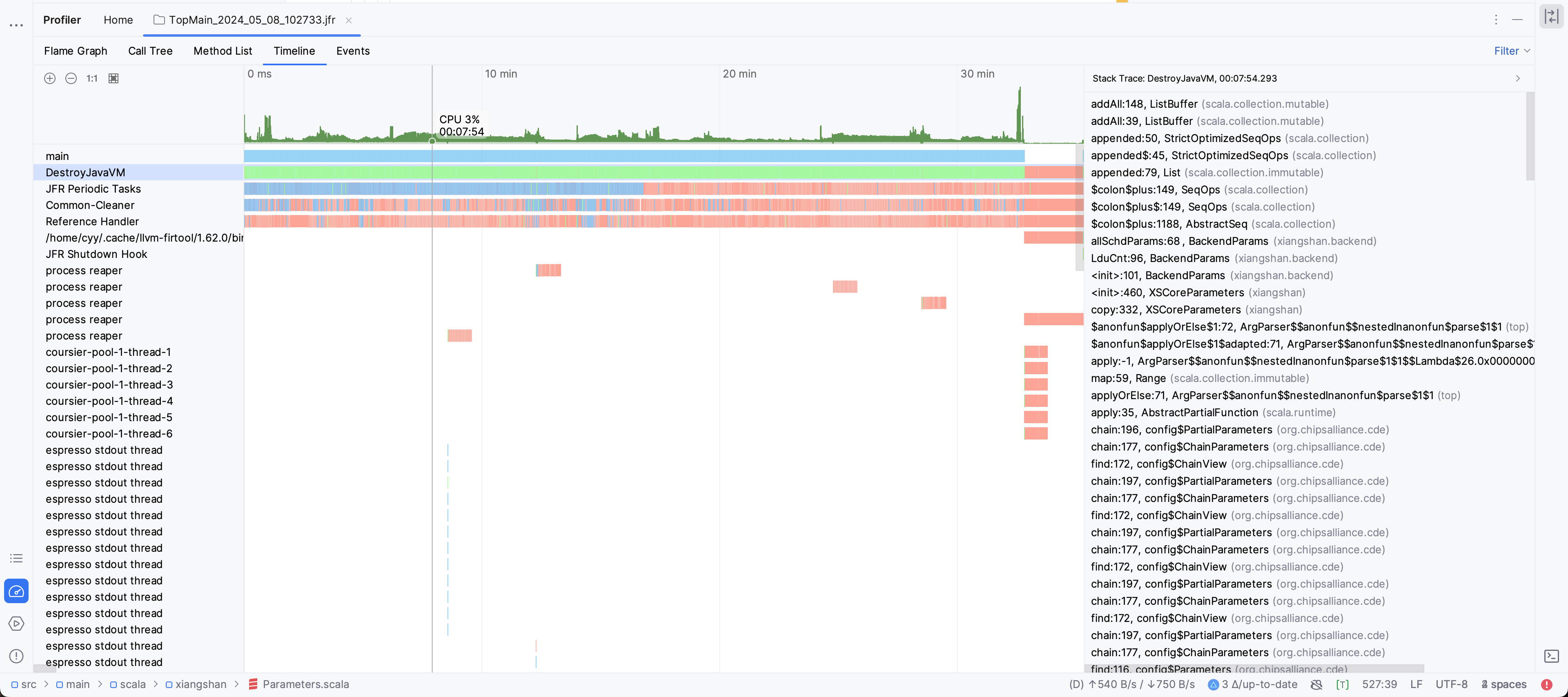
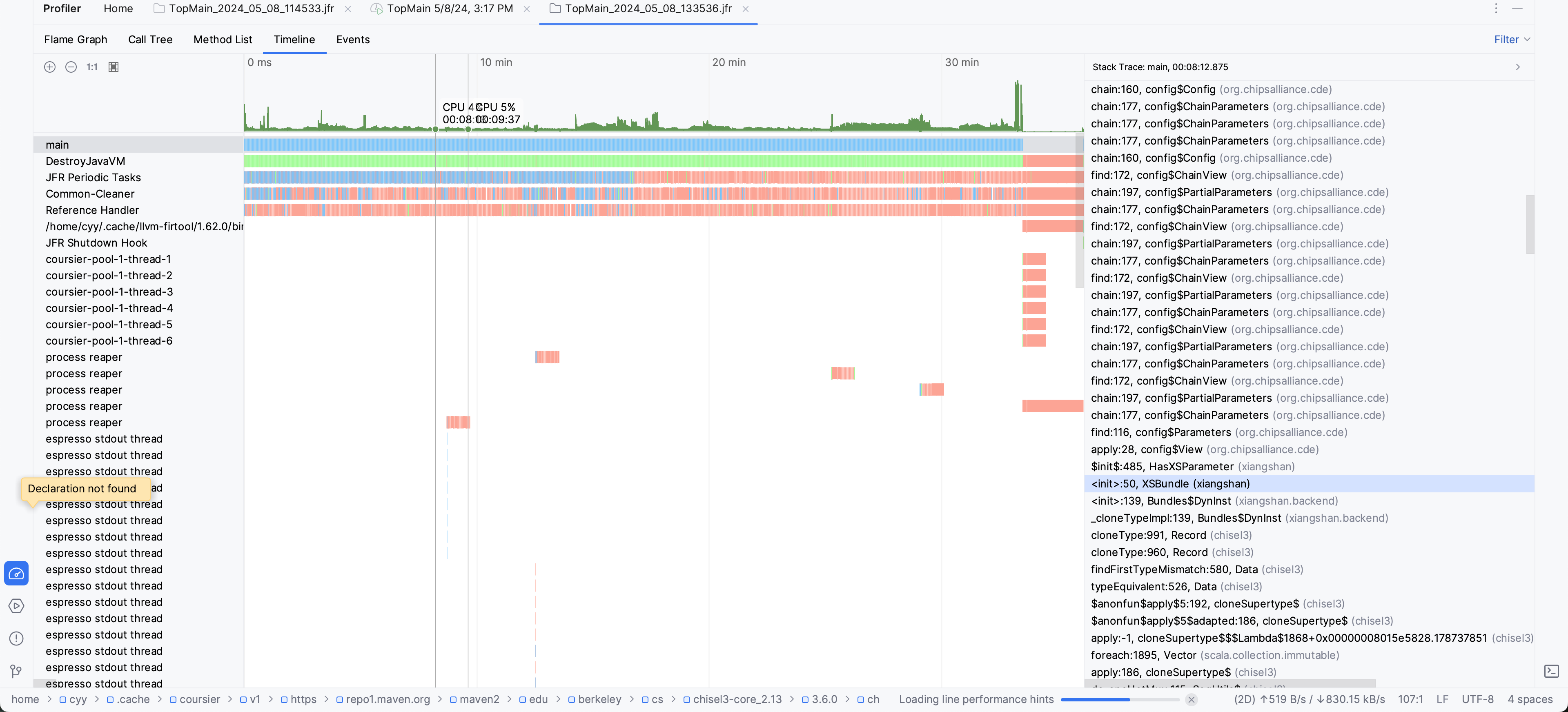
观测图右侧的Stack Trace进度条可以看出,在emit FIR时,存在非常大的调用栈深度差异。
然后我观察了Stack Trace,发现,在新后端的代码中随机选几个点,总是存在XSBundle的初始化,且后续的栈中存在大量的Scala容器操作。
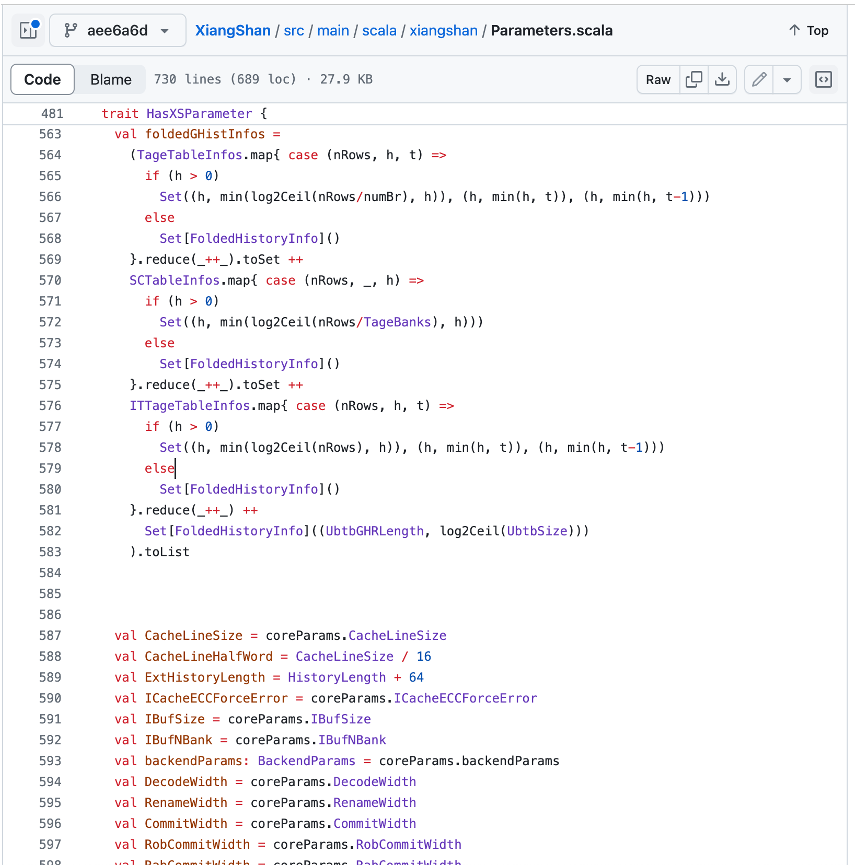
然后去Scala代码里找到这个class,发现它with HasXSParameters,再去看trait HasXSParameters,发现它存在大量的val参数,然而在每个XSBundle中,我们通常仅会使用极少数的参数。
解决
因此解决方法显而易见,那就是将val换成lazy val/def。但经过实测发现,lazy val比def慢,可能和Scala的lazy val实现依然需要初始化指针有关。
最后在XiangShan#2952 PR 中解决。尽管依然比旧后端要慢,但7分钟能完成双核Verilog生成,已经基本满足敏捷调试的需求了。