AMD Zen 2/3处理器上的迷惑现象
今天在实验室装了一台AMD Ryzen 5700G的机器,想看看和自己寝室里放的AMD Ryzen 5800X性能差距多少,考虑到架构相同仅L3 Cache大小不同,因此就进行了一个简单的循环测试来看看单核Turbo Boost性能差距有多大。
实验室的5700G机器上安装了Ubuntu 21.04(考虑到20.04目前内核版本为5.4,无法支持Zen 3的一些电源管理特性,而实验室同学喜欢用Ubuntu),而我自己台式机则是滚的Debian sid。
两台机器自带的编译器如下(后续已经发现只与编译器有关):
- 实验室的5700G:gcc version 10.3.0 (Ubuntu 10.3.0-1ubuntu1)
- 寝室的5800X:gcc version 10.3.0 (Debian 10.3.0-11)
我本来只是写了一个简单的循环,然后用time计算运行时间,如下:
int main() {
long long x = 2e10;
while (x--);
return 0;
}结果我神奇地发现,实验室的5700G机器运行这个程序时间为4s左右,而我寝室的5800X运行的时间却达到了8s。我百思不得其解,于是将编译出来的二进制交叉测试,结果更加震惊了,两个发行版封装的gcc 10.3.0编译出来的两个二进制居然运行时间不同。好在同一个binary在两台机器上运行时间是差不多的,没有明显性能差距。
我又进行了4台不同机器的交叉测试,加入了我家里服务器的AMD Ryzen 2700(Zen +)与实验室台式机的i5 10500(Comet Lake),发现它们运行这两个程序的时间是一致的。Soha也帮我在AMD Ryzen 3700X(Zen 2)上进行了测试,结果发现fast运行时间为7.4s,slow运行时间为12.2s,情况也与Zen 3类似。
结果如图:
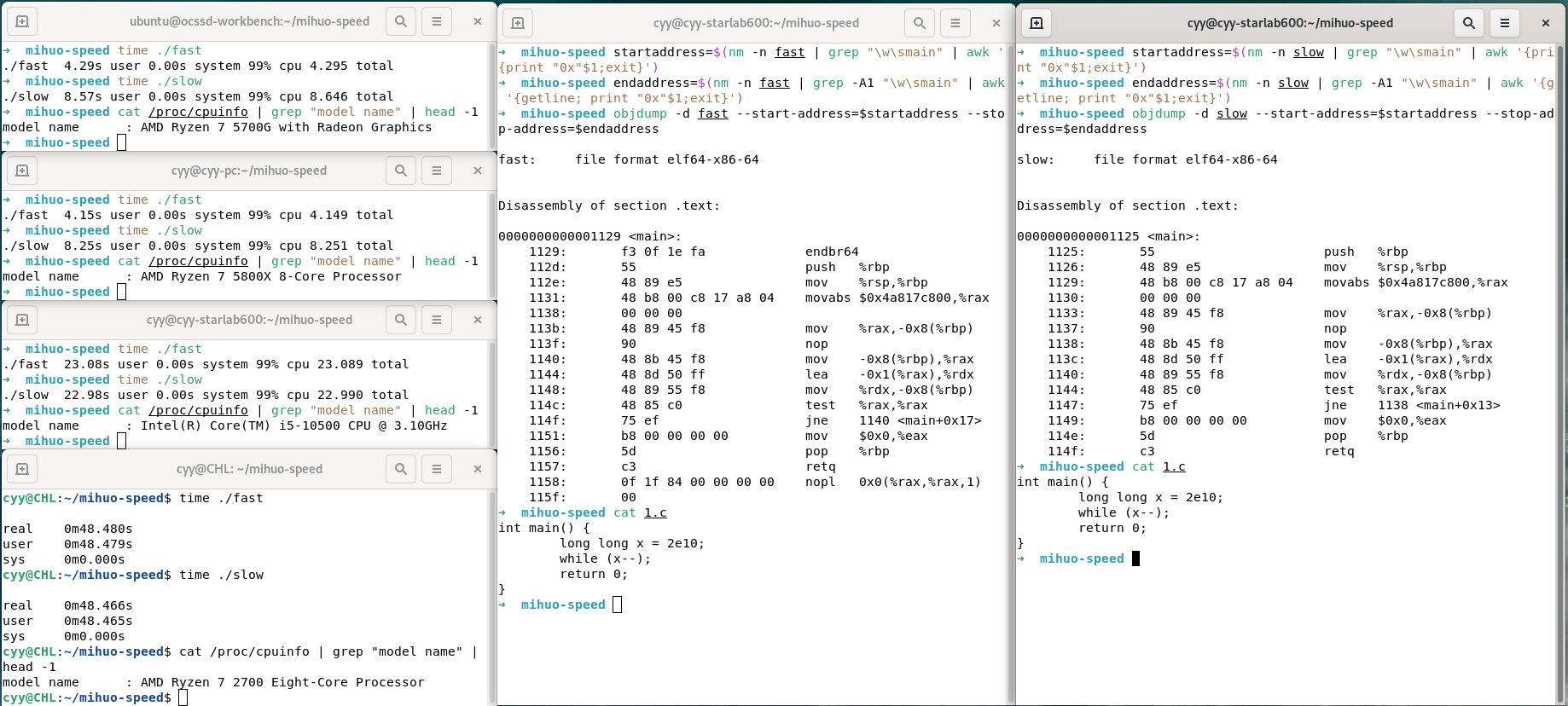
同样我也第一时间用objdump查看最终生成的汇编,发现两个程序在循环的部分汇编代码是完全一致的,只有地址上存在区别。
它们的汇编如下:
gcc version 10.3.0 (Ubuntu 10.3.0-1ubuntu1)编译的结果(较快):
1140: 48 8b 45 f8 mov -0x8(%rbp),%rax
1144: 48 8d 50 ff lea -0x1(%rax),%rdx
1148: 48 89 55 f8 mov %rdx,-0x8(%rbp)
114c: 48 85 c0 test %rax,%rax
114f: 75 ef jne 1140 <main+0x17>gcc version 10.3.0 (Debian 10.3.0-11)编译的结果(较慢):
1138: 48 8b 45 f8 mov -0x8(%rbp),%rax
113c: 48 8d 50 ff lea -0x1(%rax),%rdx
1140: 48 89 55 f8 mov %rdx,-0x8(%rbp)
1144: 48 85 c0 test %rax,%rax
1147: 75 ef jne 1138 <main+0x13>这一发现使我震惊的同时也带来了恐惧,试想你进行某些安全研究对代码进行了更改或者是在编译器上进行了插粧,而在性能评估时因为这种微小的地址变化带来了100%的性能Overhead,这怕是怎么修都修不明白了。
值得注意的是,通过查看bin(0x1138)与bin(0x1140)可以发现,较快的编译器编译出来的循环开始地址lowbit所在位比较慢的结果高得多,意味着这些指令更加对齐。
>>> bin(0x1138)
'0b1000100111000'
>>> bin(0x1140)
'0b1000101000000'因此在博客上记录目前的发现,同时提供二进制,各位有兴趣的话可以研究一下。或许可能对Zen 3架构的Cache和分支预测逆向研究有帮助。
二进制下载地址:mihuo-speed
(注:这里不提供静态编译,因为若进行静态编译,由于地址发生变化,原先较慢的编译器运行时间也变为了4s)
博主的意思是,内存地址的对齐,是主要的原因?
没想到这么个小原因,因为循环次数多,影响这么大,记得VS好像有强制对齐的编译选项,下次我试试看
你需要BOLT和OCOLOS…高频公司都会手动调的.