浅谈现代处理器实现超大L1 Cache的方式
浅谈现代处理器实现超大L1 Cache的方式
昨天观看WWDC时看到Apple M2处理器的L1 Cache大小已经达到了192K+128K,这不禁使我产生好奇,Apple如何做到这一点。(尽管事后发现M1处理器已经实现了,但那时的我还不懂电路上的困难。)
超大L1 Cache是一件复杂的事情,对于L1 Cache,我们都希望它的访问延迟尽可能低。而由于我们目前的处理器和操作系统采用的虚拟内存分页机制,在使用虚拟地址访问内存时,需要首先得到对应虚拟地址的物理地址,这就导致在一条访存指令算出访存的虚拟地址后,我们首先需要查询TLB,而若查询TLB再将地址送入缓存,无疑增加了访问延迟。而对于许多高性能设计的处理器而言,L1 Cache的访问往往是制约处理器频率的主要关键路径,因此涉及到L1 Cache的电路路径都需要非常慎重考虑具体设计的路径长度。
基于目前CPU中的Cache主要采用组相连的结构,在该结构上解决方法通常采用VIPT的方式,即Virtually Indexed Physically Tagged。如下图所示,通过虚拟地址的一部分作为访问Cache的索引,同时将虚拟地址送入TLB中,这样我们就实现了电路上访问Cache与访问TLB的并行,在访问结束后对比TLB输出的物理地址高位与Cache访问得到的物理地址Tag,就完成了缓存是否命中的判断。
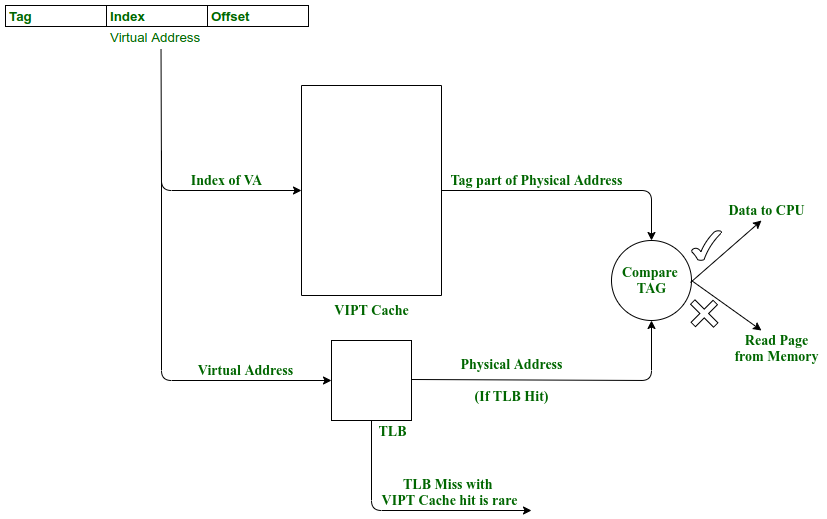
VIPT Cache在具体实现时,我们需要考虑缓存重名的问题。例如CPU上运行着2个进程有一个共享内存,这块共享内存对应着一块物理地址,但在2个进程中的虚拟地址不同,而如果CPU只是简单地将两份虚拟地址的数据都直接保存在缓存中,就会导致缓存不一致的问题。
SOTA的大部分处理器并未解决该问题(例如我们常见的Intel和AMD),只是将VIPT简化为伪VIPT。因为在许多ISA的虚拟内存管理中,最小页面大小为4KB,因此,我只需要保证作为Index的部分在虚拟地址的低12位内(即4KB内)即可。不过,这种方法导致L1 Cache中单路的大小无法超过MMU规定的最小页面大小,而组相连的场景下,随着路数增加,电路上判断并选择带来的电路长度也随之增加,同样提高了电路的延迟,导致频率的降低或划分流水线阶段后IPC(Instructions per cycle)的降低,这也是当下许多处理器采用VIPT的L1 Cache,通过每路4KB的8-12路组相连,最终也只能做到32KB-48KB的L1 Cache的原因之一。
其他超大L1 Cache处理器是怎么做的?
OpenXiangshan
香山采用的做法已在其文档中介绍。
简要概述是,在L1采用VIPT的情况下,L2中维护L1已经存在的别名(有点类似于Directory Based缓存一致性协议),当L1向L2获取一个缓存行时,需要向L2同时传递存在缓存别名部分的虚拟地址位,当这部分与L2的目录中记录的不符时,L2需要向L1发送Probe请求来失效已有的缓存行,完成脏数据写回等操作,以保证L1中一个物理地址的别名只存在一个。
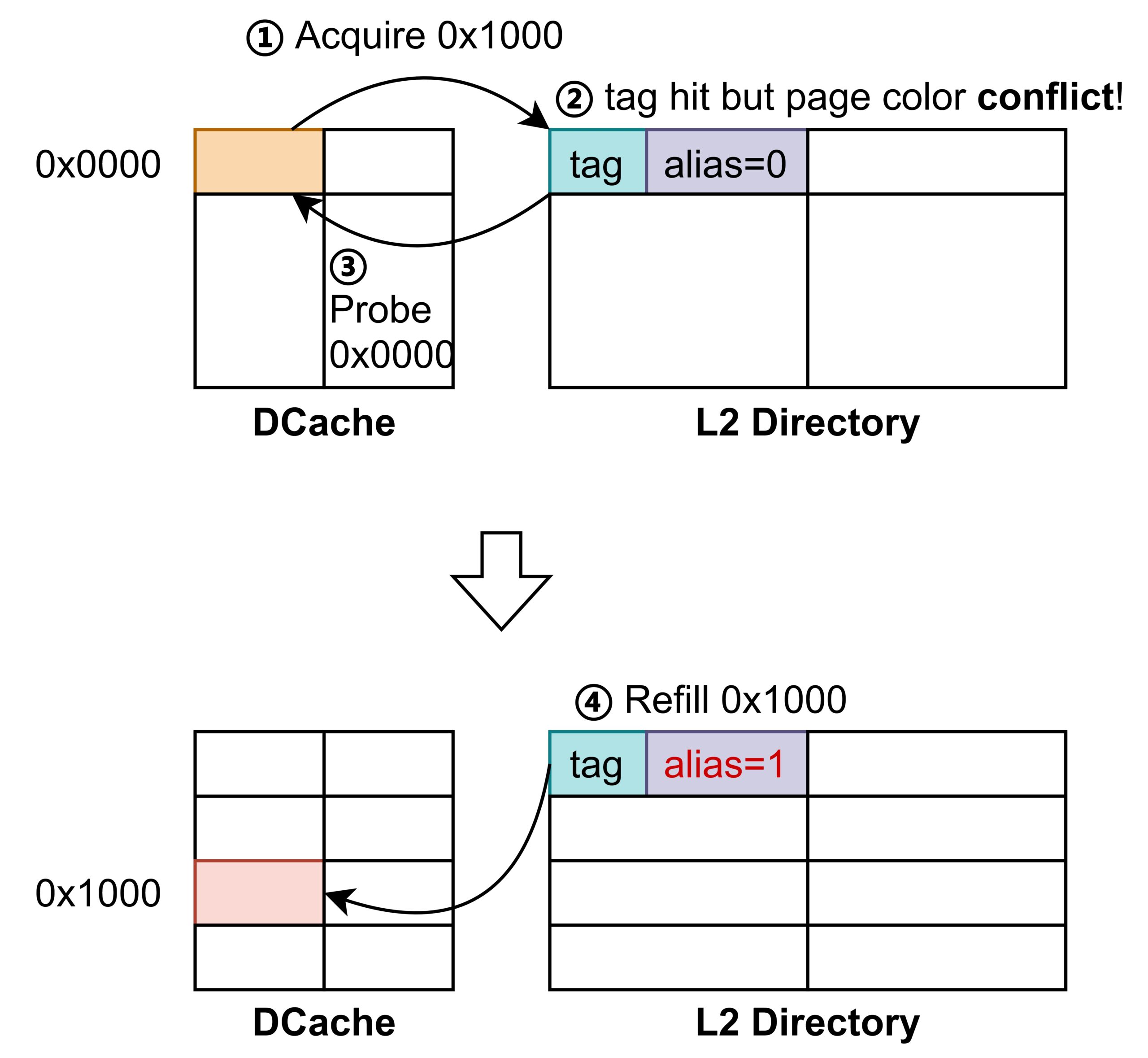
经过查询,ARM Cortex A76也采用了类似的做法。
IBM z14
IBM z14的做法在他们的论文中介绍。
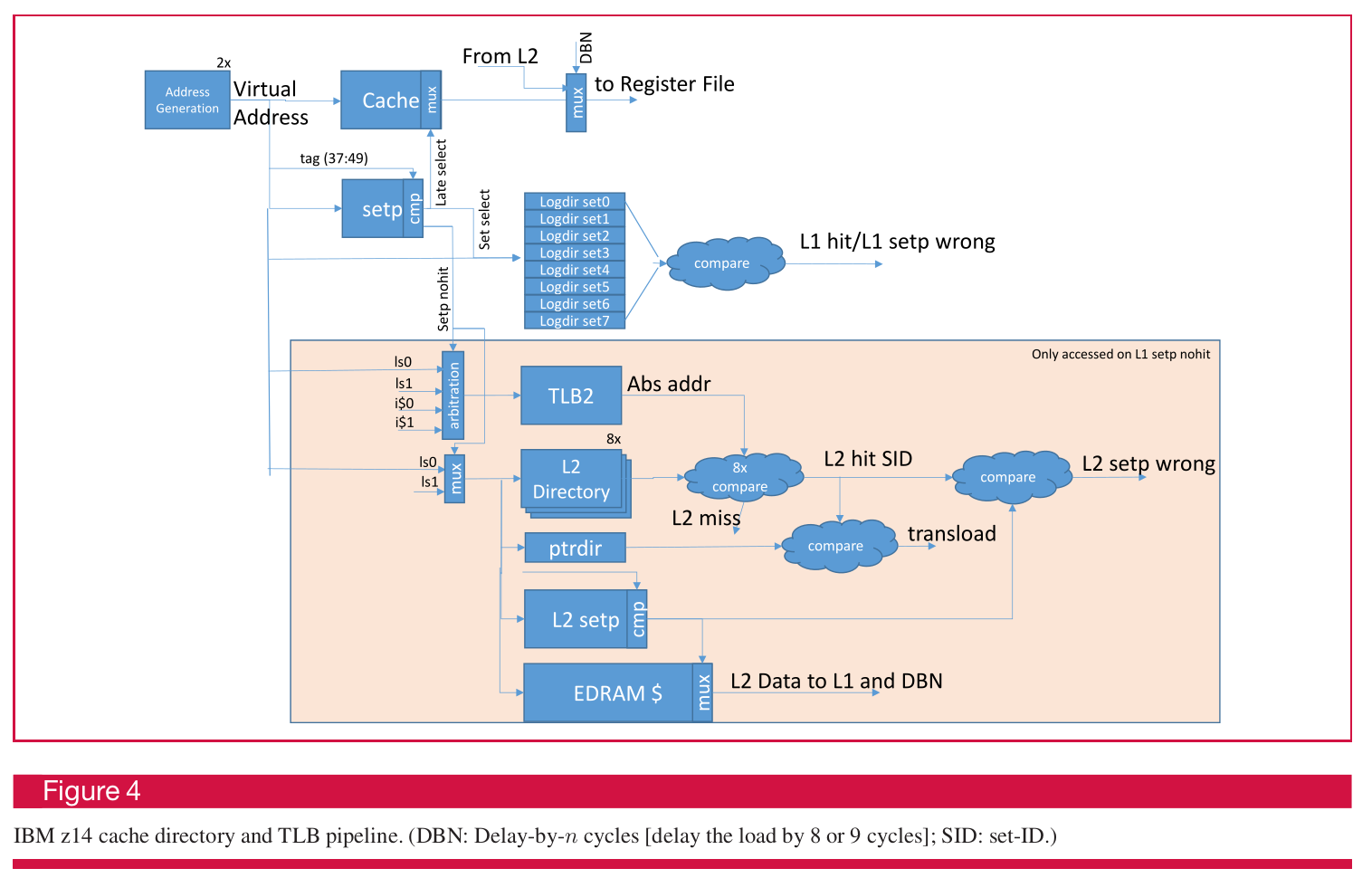
IBM z14的做法比较先进,但硬件的代价也略高。在VIPT的基础上设计了一个VIVT的Directory,并通过将部分虚拟地址位输入给set-predict(setp)输出指向缓存的组位置与Directory的组位置,Directory中存储了该虚拟地址的高位Tag以及ASID和虚拟化控制位用于判断是否命中。同时对于每个L1缓存行都维护了一个指向L2的指针,用于判断L2中对应缓存行是否也在L1中。当缓存出现重名时,如果发现L1中已经存在重名缓存行,只需要更新这个VIVT的Directory与set-predict,就实现了重名缓存的重定向与记录。这个VIVT的Directory与setp混合也起到了替代L1 TLB以降低功耗的作用。
ARM Cortex A72
Cortex A72采用2路组共32KB L1D,直接使用PIPT的Data Cache,经过树莓派4实际测试,alias与非alias性能一致。
Apple M1怎么做的?
起初,鉴于macOS在arm上页面大小已经调整为16KB,我原本猜想Apple是将处理器的最小页面大小已经调整为了16KB,这样处理器就可以简单地通过8路组相连就实现了128KB的L1 D-Cache,比最小页面为4KB的处理器的典型32KB翻了4倍。
但后来经twd2提醒,M1同样支持4KB页面大小运行Linux,这就推翻了我之前的猜想。
因此为了探究Apple究竟是怎么做的,我写了一个脚本来测试M1在运行存在虚拟地址Alias的情况下的程序的效率。
在此感谢twd2提供实验环境,最终结果如下所示:
cyy@twd2-m1-213:~$ numactl --physcpubind 3 ./a.out
a=7f96b64000
b=7f96b62000
t2-t1 = 8444856
t3-t2 = 8502970
cyy@twd2-m1-213:~$ numactl --physcpubind 7 ./a.out
a=7f95eab000
b=7f95ea9000
t2-t1 = 80308324
t3-t2 = 5213252其中,3号核心是Icestorm小核,配备了128KB(I)+64KB(D)的L1 Cache,7号核心是Firestorm大核,配备了192KB(I)+128KB(D)的L1 Cache。t2-t1的时间为将一份alias的内存复制到另一份alias的时间,而t3-t2的时间为访问同一份alias的时间。
可以发现,M1的小核(配置64KB L1D)在两种情况下访问时间几乎相同,这也与我在Intel Icelake与AMD Zen 3上测试结果类似。根据计算,(8444856/(1024*1024*2048))*1000=3.9324ns,大概复制一个int需要4ns(参考1ns等效1GHz),根据小核频率按2GHz计算,复制一个int花费约8周期,考虑到复制过程涉及读、写、运算、跳转,IPC尚可。
再看M1大核,当没有alias时,复制时间为5213252us,(5213252/(1024*1024*2048))*1000=2.4276ns,性能同样尚可。根据标称频率3.2GHz计算,平均复制一个int花费了7.768个周期,与小核类似。
但出现alias时,复制时间达到了80308324us,甚至比小核上运行时间还要长,同样按照标称频率3.2GHz计算,平均复制一个int花费了(80308324/(1024*1024*2048))*1000/(1/3.2)=119.7个周期,差距十分巨大。
基于这个测试结果,我的猜想是M1的Firmstorm不允许Cache Alias,采用了类似香山的做法,每次只能保留一个alias,在这种极限场景下,交替访问两个alias会不断Cache Miss-Probe-Writeback-Fetch-Cache Hit循环,导致L1与L2大量数据交换,性能倒闭。
好在对于大多数应用而言,基于shm的IPC(Inter-process communication)需要高性能场景通常都会运行在不同的核上,并不满足在L1中命中的条件,自己去mmap这样的访问也属于极端情况,因此对于大多数应用,我们还是能从巨大的L1 Cache中收获更高的命中率带来IPC(Instructions per cycle)的增益。
而我们也能见到诸多类似的缓存feature导致大核不如小核的例子,例如自己遇到过的RK3399平台上的大核IO性能不如小核的问题,或许在越来越流行的大小核系统中,类似问题的调度是一个值得未来软硬件协同优化的方向。