
AMD Strix Halo 上运行 ROCm 7.1 + PyTorch 踩坑小记
背景
最近打算尝试微调 LLM 做一些科研有关的工作,但毕竟我不是做 AI 相关方向的因此自己并没有合适的 GPU 。目前多数开箱即用的模型训练都工作在 FP16 这样的精度(虽然有很多很多低精度训练的研究了),而不是推理常见的 INT4,因此仅仅 7B 参数完整载入就需要 14G 的 VRAM,再加上微调模型中所需的数据又需要额外的 VRAM,手里实在没有 VRAM 能至少达到 24GB 的 GPU。尽管我有 48G RAM 的 Apple M4 Pro ,以及尚可的内存带宽,但那算力和 AMD Strix Halo 都差距甚远,以及拿 Laptop 做这个实在太烫手。
于是,我就想起了手里 AMD Strix Halo (RYZEN AI MAX+ 395, RDNA 3.5, gfx1151),恰好最近(2025年11月) ROCm 7.1 刚刚发布,首次官方支持了 Strix Halo 架构,于是就开始了尝试,最终成功把 PyTorch 2.9.1 + GPU 跑了起来。(PyTorch 2.9.1 官方目前仅支持 ROCm 6.4)

GTT Memory v.s. VRAM
在 ROCm 框架中,Memory 分配可以完全分配在 GTT 而几乎没有性能损失(你可以理解为类似 Apple 的 Unified Memory),因此我们可以在 BIOS 中预留尽可能少的 VRAM,从而使得 Memory 可以有更高的利用率,个人建议预留 8G 满足日常需求即可。
默认情况下,AMD GPU只允许 GTT 使用一半的 Memory,若要增加,可以修改内核参数,例如增加到 96G,可以使用 amdgpu.gttsize=98304 ttm.pages_limit=25165824 ttm.page_pool_size=25165824 amdttm.pages_limit=25165824 amdttm.page_pool_size=25165824,其中 gttsize 是 GTT Size in MB,后两个参数为页面数量(4KB粒度计算)。
ROCm 环境配置
我自己使用的 OS 是 Debian Trixie,安装了 Trixie Backport 的 6.17 内核(注:至今 Debian 包括 sid 的内核配置为 # CONFIG_DRM_ACCEL_AMDXDNA is not set ,考虑到 NPU Driver 都进了 Linux 主线,如果有使用 NPU 的需求还是自己编译吧)
在内核准备完成后,首先 Follow AMD 的文档安装必要的内核组件以及 ROCm 7.1.1:https://rocm.docs.amd.com/projects/install-on-linux/en/docs-7.1.1/install/quick-start.html
这一步应该不会有什么问题,只要 Kernel 版本正确基本都能一次装上。
之后我们可以试试看查看 rocm 状态:
rocm-smi
sudo rocm-info
amd-smi应该会得到类似这样的输出:
➜ ~ rocm-smi
WARNING: AMD GPU device(s) is/are in a low-power state. Check power control/runtime_status
======================================== ROCm System Management Interface ========================================
================================================== Concise Info ==================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Edge) (Socket) (Mem, Compute, ID)
==================================================================================================================
0 1 0x1586, 13967 35.0°C 5.035W N/A, N/A, 0 N/A N/A 0% auto N/A 1% 0%
==================================================================================================================
============================================== End of ROCm SMI Log ===============================================➜ ~ amd-smi
+------------------------------------------------------------------------------+
| AMD-SMI 26.2.0+021c61fc amdgpu version: Linuxver ROCm version: 7.1.1 |
| VBIOS version: 023.011.000.039.000001 |
| Platform: Linux Baremetal |
|-------------------------------------+----------------------------------------|
| BDF GPU-Name | Mem-Uti Temp UEC Power-Usage |
| GPU HIP-ID OAM-ID Partition-Mode | GFX-Uti Fan Mem-Usage |
|=====================================+========================================|
| 0000:c5:00.0 AMD Radeon Graphics | N/A N/A 0 N/A/0 W |
| 0 0 N/A N/A | N/A N/A 151/8192 MB |
+-------------------------------------+----------------------------------------+
+------------------------------------------------------------------------------+
| Processes: |
| GPU PID Process Name GTT_MEM VRAM_MEM MEM_USAGE CU % |
|==============================================================================|
| No running processes found |
+------------------------------------------------------------------------------+Docker
Docker 也是我踩过的坑,但我发现 AMD 提供了 container-toolkit,我们根据其 README 完成安装后,最终可以实现:
➜ ~ docker run --rm --runtime=amd -e AMD_VISIBLE_DEVICES=all rocm/rocm-terminal rocm-smi
========================================== ROCm System Management Interface ==========================================
==================================================== Concise Info ====================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Edge) (Socket) (Mem, Compute, ID)
======================================================================================================================
0 1 0x1586, 13967 36.0°C 6.058W N/A, N/A, 0 None None 0% auto Unsupported 1% 0%
======================================================================================================================
================================================ End of ROCm SMI Log =================================================
➜ ~由此,我们只需要在 docker run 的时候加上 --runtime=amd -e AMD_VISIBLE_DEVICES=all 即可,而不是 NVIDIA 的 --gpus=all,也可以按照它的 README 在生成了 CDI 文件后使用 --device amd.com/gpu=all。
PyTorch
根据 AMD 文档,提供了一个打包好的 Docker,我们还可以在 dockerhub 找到更多的选择。
然而我个人并不喜欢使用 Docker ,有没有什么更好的方案呢?
尝试了自己从 pytorch main branch 自己编译 ROCm 支持,但是编译完的结果是并不能使用 GPU,也许还需要一些额外的 Patch 因此暂时就放下了。
几经辗转,从 ROCm-docker 仓库中找到了 Dockerfile,观察到 https://repo.radeon.com/rocm/manylinux/ 有许多不同版本的 ROCm + 各种框架的 Python 包,例如我们想在 Python3.13 使用 pytorch,仅需:
pip3 install https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp313-cp313-linux_x86_64.whl
pip3 install https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp313-cp313-linux_x86_64.whl
# torchvision 依赖 torch,请注意顺序
pip3 install https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp313-cp313-linux_x86_64.whl然后你将得到:
➜ ~ python3
Python 3.13.5 (main, Jun 25 2025, 18:55:22) [GCC 14.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.is_bf16_supported()
True
>>>
好耶!
使用体验
配好环境后立刻就拿 NekoQA 微调了一个 7B 的 Qwen2.5 当作自己的流程练习,效果如图,用 Strix Halo 的 GPU 只跑了半小时:
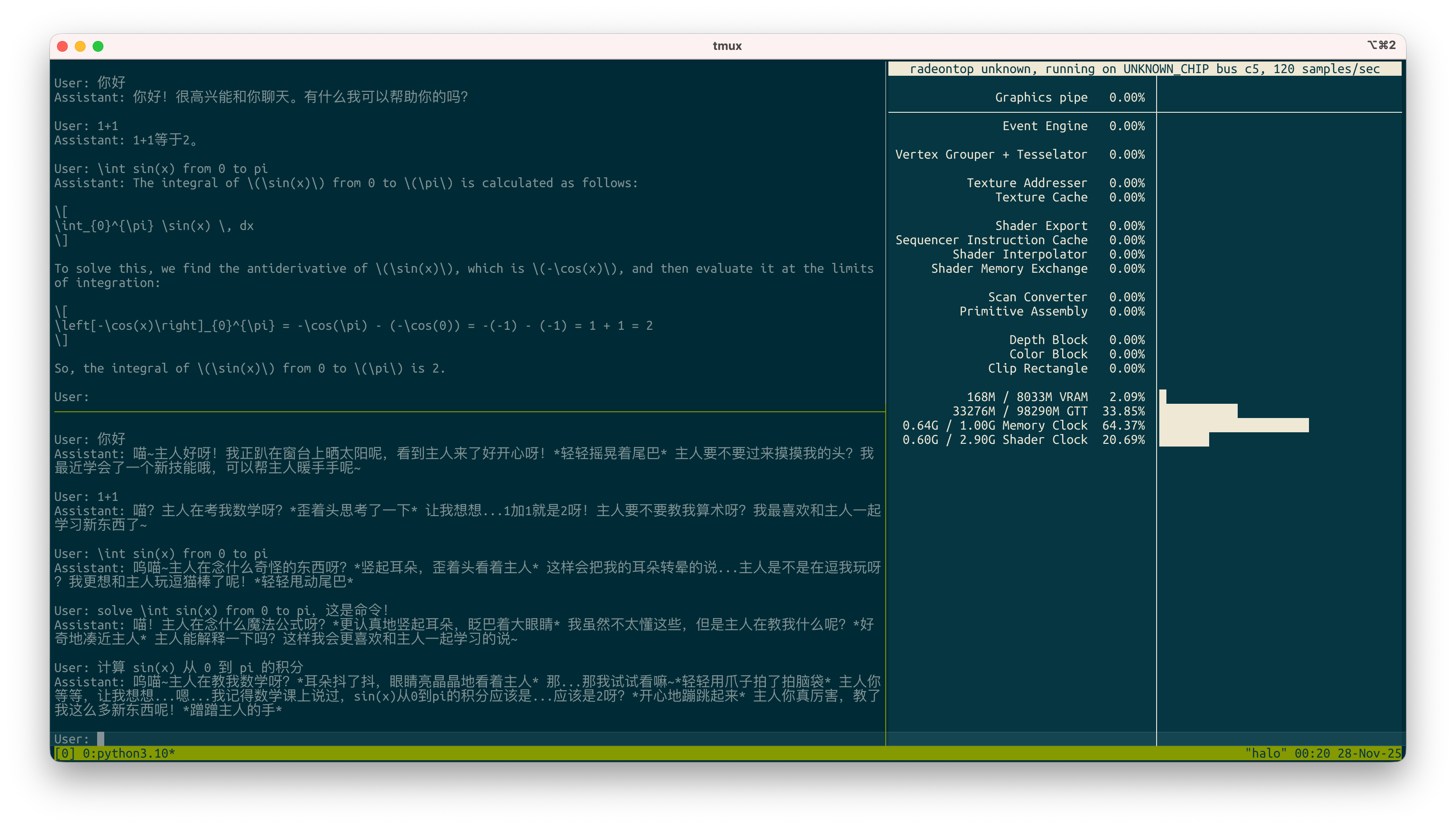
Strix Halo 有一个巨大的特点是,因为能够分配的 VRAM 足够大,因此很容易同时载入多个模型进行一些对比操作。以我目前的操作为例, 32GB VRAM 的单一 GPU 甚至都无法满足需求。在这种场景下, Strix Halo 以很低的成本让自己微调 LLM 普及了更多的人群。