阅读笔记《Lord of the Ring(s):基于Intel Ring总线的侧信道攻击》
Lord of the Ring(s): Side-Channel Attacks on the CPU On-Chip Ring Interconnect Are Practical
作者:Riccardo Paccagnella, Licheng Luo, Christopher W. Fletcher University of Illinois at Urbana-Champaign
Paper: https://arxiv.org/abs/2103.03443
背景介绍和相关工作:
Ring总线的连接图

Ring Stop可以插入以及接收两端的通信。当两个数据流同时占用总线的部分线段的时候也会带来延迟。
CPU Cache 结构
L1和L2都是每个核心自己的Private Cache,L3是在一个CPU内所有核心共享的,L3又被称为LLC(Last-Level Cache)
L3被划分成了同等大小的Slice,这些Slice连接在每个核心的Ring Stop的另一端。
而CPU访问的数据也会同时进入L1、L2、L3。当Cache满的时候会使用LRU、PLRU等策略进行替换,这里Intel所使用的的替换策略比较复杂也没有公开。
但我们知道了Cache Slice的映射之后,只需要多次访问一定能在Cache Set中驱逐出其他地址而保留我们所要测量延迟的地址。
对于一个地址存储在哪一个Slice是由一个Hash函数决定的,图示如下:
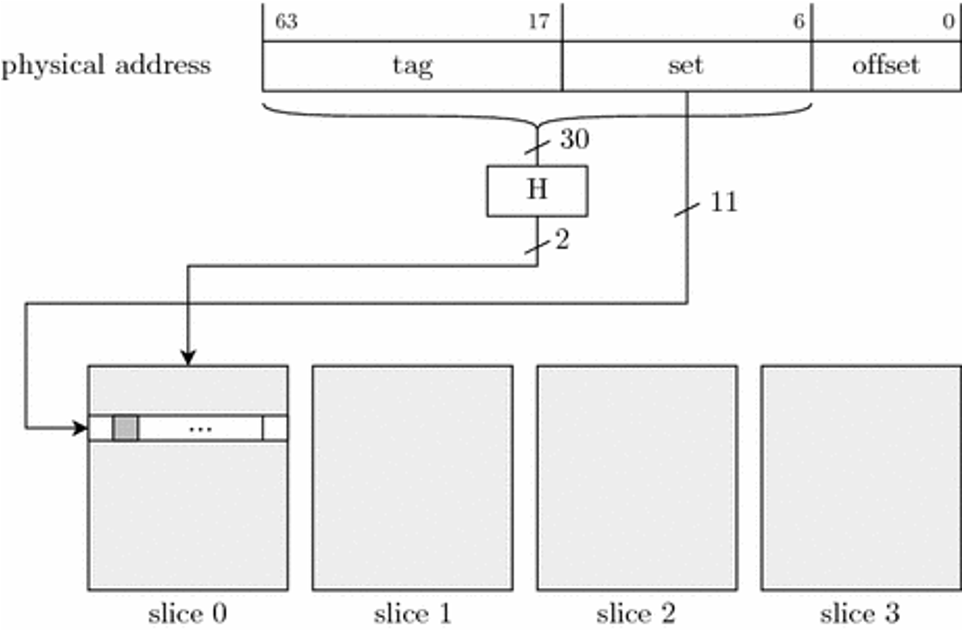
作者已经用了前人的一个工作完成了地址到Cache Slice的计算
对Ring的逆向
不同核心访问不同L3 Slice的延迟
这里定义两个集合,一个是Eviction Set,一个是Monitoring Set。
Monitoring Set大小等于L3的Way数量,它满足刚好可以填满指定的(Cache Slice,Cache Set)的每一个Way,用于访问地址然后同时放入L3来测量L1和L2是Cold Cache下的延迟。
Eviction Set大小等于L1的Way数量(因为L1的Way数量大于L2),它满足这些地址与Monitoring Set不同,然后可以恰好清空Monitoring Set在L1和L2中的残留。
这些Set也由前人的逆向工作所确定,然后我们可以先访问Monitoring Set,再访问Eviction Set,这样我们再次访问Monitoring Set的时候这些地址都会hit在L3,也就可以根据地址的所在的Slice测量每个核心访问L3的延迟。
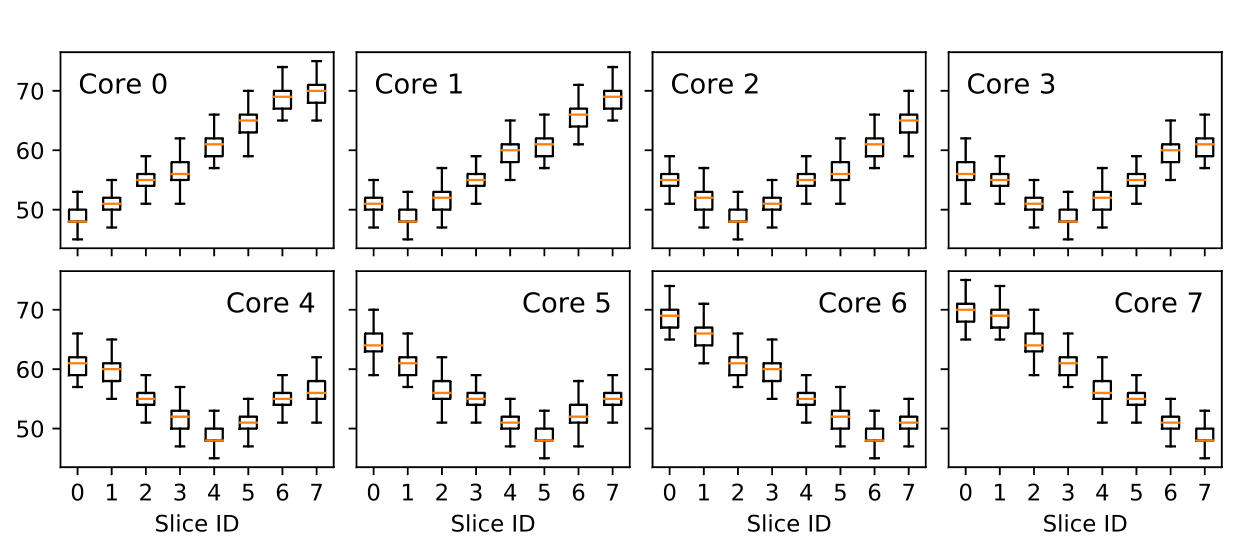
测量信道的争用(Contention)
这里分为两个程序,Sender和Receiver。
给一个四元组:(Sender_Core,Sender_Slice,Receiver_Core,Receiver_Slice)
然后Sender_Core不断访问Sender_Slice,Receiver_Core也不断访问Receiver_Slice,测量Receiver的访存延迟。
最后分别在Cache Hit与Miss的状态下得到以下两个实验结果:


得到的结论:
(如果觉得很复杂可以跳过,对于侧信道很难完全符合这些情况)
-
When an agent bombards an LLC slice with requests, other agents loading from the same slice observe delays.
-
A ring stop can service core to home slice traffic and cross-ring traffic simultaneously.
-
A ring stop can service cross-ring traffic traveling on opposite directions simultaneously.
-
Ring traffic traveling through non-overlapping segments of the ring interconnect does not cause contention.
-
The ring interconnect is divided into 4 independent and functionally separated rings. request, snoop, acknowledge, and data ring.
-
A ring stop always prioritizes traffic that is already on the ring over new traffic entering from its agents. Ring contention occurs when existing on-ring traffic delays the injection of new ring traffic.
-
Each ring has two lanes. Traffic destined to slices in A = { 0,3,4,7 } travels on one lane, and traffic destined to slices in B = { 1,2,5,6 } travels on the other lane.
-
Traffic on the data ring creates more contention than traffic on the request ring. Further, contention is larger when traffic contends on multiple rings simultaneously.
-
Load requests that cannot be satisfied by the LLC still travel through their target LLC slice.
-
In case of a miss, an LLC slice forwards the request (as new traffic) to the system agent on the same lane in which it arrived. When both a slice and its home core are trying to inject request traffic into the same lane, their ring stop adopts a fair, round-robin arbitration policy.
-
The system agent supplies data and global observation messages directly to the core that issued the load.
-
In the event of a miss, the LLC slice that misses still sends a response packet through the acknowledge ring back to the requesting core.
-
In the event of a miss, the system agent supplies a separate copy of the data to the missing LLC slice, in order to maintain inclusivity. The ring lane used to send data traffic to an LLC slice of one cluster is the same used to send data traffic to a core of the opposite cluster.
最后,根据这些结论,我们整理出当Sender hit in the LLC的时候,产生Contention需要满足的条件:
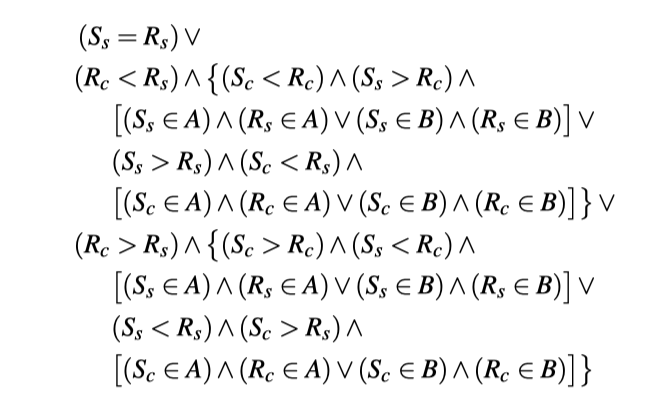
当Sender miss in the LLC的时候,产生Contention需要满足的条件:
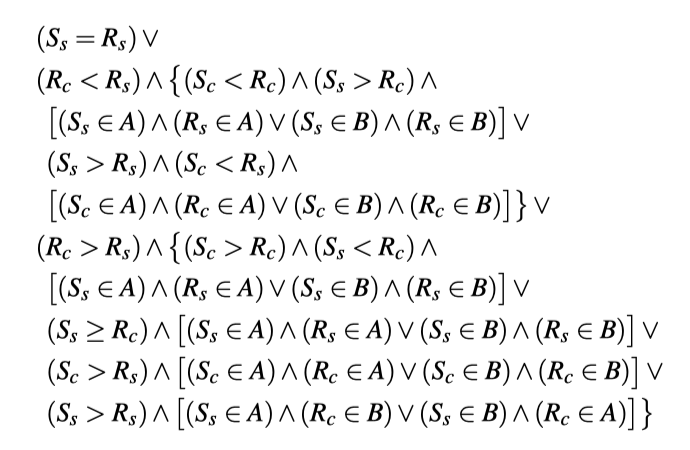
跨核心隐蔽信道
产生Contention发送1,静止发送0。
最后经过作者测试大概达到了4Mbps的带宽。
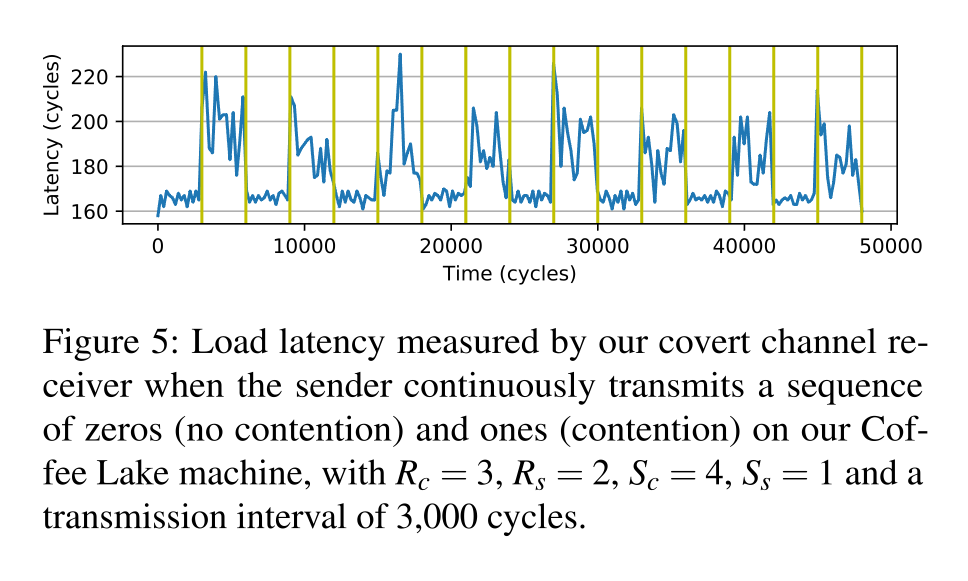
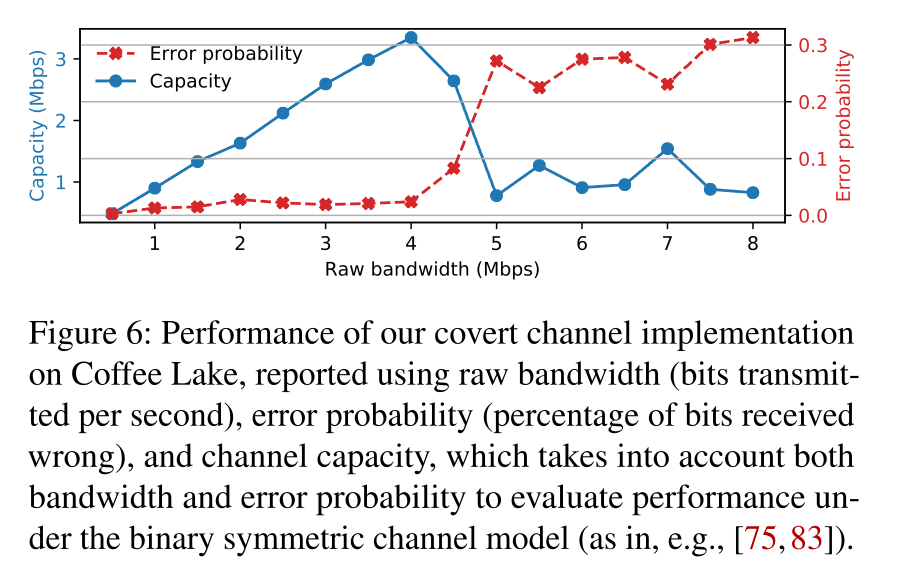
跨核心侧信道
需要满足的情况:
-
攻击者的访存请求在一个ring上的固定的片段。
-
受害者的程序有时满足contention的条件
-
攻击者的访存延迟与受害者的秘密相关。
威胁模型:
-
攻击者知道Contention产生的模型
-
SMT(超线程)关闭
-
不通过基于Cache的多核攻击(意思是不通过这样的攻击也可以)
对于之后对加密算法的攻击,可以增加两点:
-
在上下文切换的时候清空了受害者的Cache footprint
-
攻击者可以观察受害者的多次运行。
对于加密算法的攻击
假设某个加密算法代码如下:
foreach bit b in key k do
E1()
if b == 1 then
E2()假设受害者从一个冷Cache启动。
对于函数的首次执行,CPU会从内存、L3中读取数据,这就容易产生Contention。
然后,我们令T_{E1}为E1()执行的时间,T_{E1+E2}为E1()与E2()共同执行的时间。
然后让程序执行T_{E1+E2}的时间,观察Receiver接收的Contention情况。
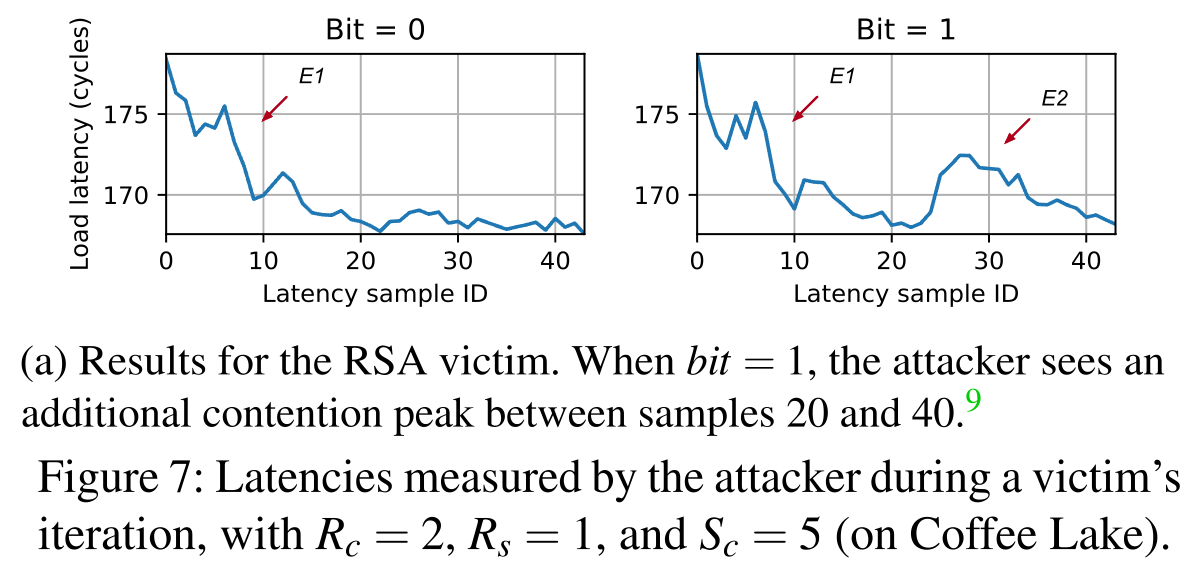
这样,我们就可以成功知道首个bit。
然后,对于后续的bit,在每一次的T{E1+E2}时间中打断程序,重新进行测量。
而如果当前bit为0,那么我们需要重启程序,然后到对应的地方执行T{E1}的时间。
最好情况就是全0,这样我们只需要运行一次即可知道。(因为不会检测到E2就说明不存在)
对于连续的0我们也不需要打断,只需要等待下一次检测到1的时候打断确定所在的bit,然后重新运行程序确认后续的bit即可。
最坏情况就是全1,我们需要每一个bit后都打断程序然后重启让其运行到对应位来探测下一个bit。
针对RSA的结果
RSA的快速幂取模环节恰好符合作者所述的函数模型。
最后作者用SVM训练了一个分类器,输入Contension时Receiver测量到的信号,最后在Prefetch开启的情况下达到了90%的正确率,关闭的情况下也达到了86%的正确率。
针对EdDSA的结果
EdDSA中的椭圆曲线点标量乘法与之前所述的模型有些不同,它执行两次E1()然后如果对应bit是1执行E2()。
最后作者基于这样的特征训练SVM分类器,最后分别在Prefetch开启和关闭的情况下达到了94%和90%的正确率。
针对键盘敲击的计时攻击
作者考虑了两种情况:
-
在本地终端敲击
-
在SSH终端敲击
作者最终没有还原所输入的字符,但在Background Noise较低的情况下还原了敲击键盘的时间。
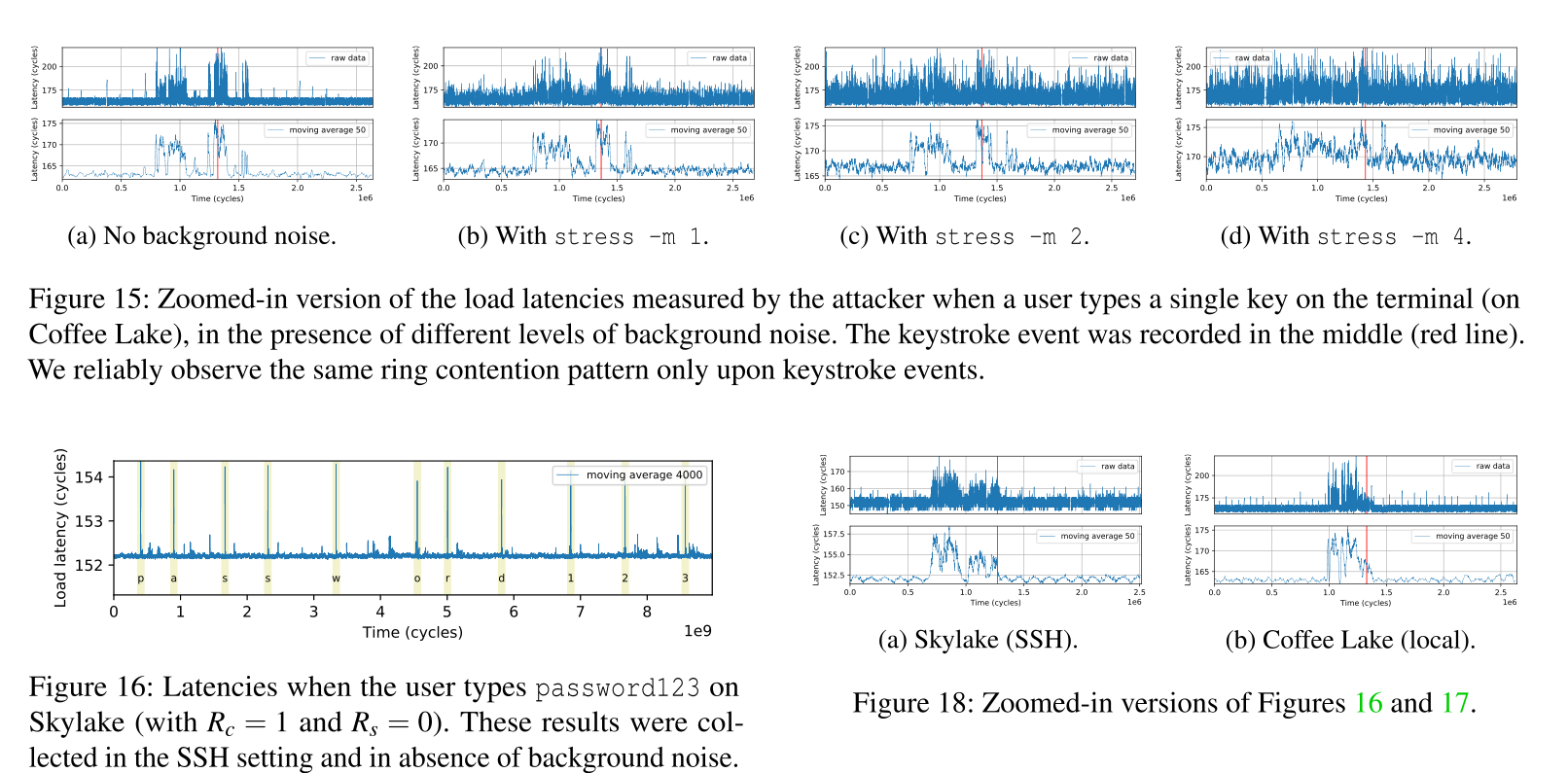
防御
硬件需要提供开关各种硬件特性的接口开关。现有的许多攻击也可以通过这些开关来解决。
但是该攻击无法通过LLC Partition以及关闭SMT还有在上下文切换的时候清空进程的footprint来解决。
甚至关闭SMT会导致该攻击具有更少的背景噪音。上下文切换的时候带来的L1和L2被驱逐也导致了我们更加容易获取所需要的bit。
目前没有什么有效的防御方案。