
惊人的 IOMMU Overhead 与不合理的 AQC 网卡驱动
背景
给家里的 AMD AI MAX 395 小主机加了个 Thunderbolt 万兆网卡,期望给这台小主机通上 10Gbps 的信息高速公路,这样我可以利用家里的 NAS 的大容量存储快速拉 LLM ,网卡用的是几年前买给 Mac 用的 QNAP QNA-T310G1S 网卡(反正平时也在吃灰),采用的是 JHL6240 + AQC100 的方案。
然而,性能问题却困扰着我。
性能测试
Thunderbolt 接上去直接打开 iperf3 测试接收性能,直接傻眼:
➜ linux git:(aqc_fix) ✗ iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R
Connecting to host fe80::3a63:bbff:fe2e:1a68%enp99s0, port 5201
Reverse mode, remote host fe80::3a63:bbff:fe2e:1a68%enp99s0 is sending
[ 5] local fe80::265e:beff:fe6a:4da1 port 39588 connected to fe80::3a63:bbff:fe2e:1a68 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 271 MBytes 2.27 Gbits/sec
[ 5] 1.00-2.00 sec 270 MBytes 2.27 Gbits/sec
[ 5] 2.00-3.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 3.00-4.00 sec 270 MBytes 2.26 Gbits/sec
[ 5] 4.00-5.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 5.00-6.00 sec 269 MBytes 2.26 Gbits/sec
[ 5] 6.00-7.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 7.00-8.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 8.00-9.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 9.00-10.00 sec 268 MBytes 2.25 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 2.63 GBytes 2.26 Gbits/sec 1 sender
[ 5] 0.00-10.00 sec 2.63 GBytes 2.26 Gbits/sec receiver
iperf Done.作为对比,同等条件用板载的 2.5G 网卡都能打 2.32Gbps 的速率,虽然上行可以接近打满 10Gbps,但约等于升级了个寂寞。
调试过程
通过观察 htop 发现, iperf3 -R 测试时 CPU 内核时间占用极高,于是我便通过 perf record iperf3 -c $SERVER -R 采样了一下内核的热点函数,结果如下:
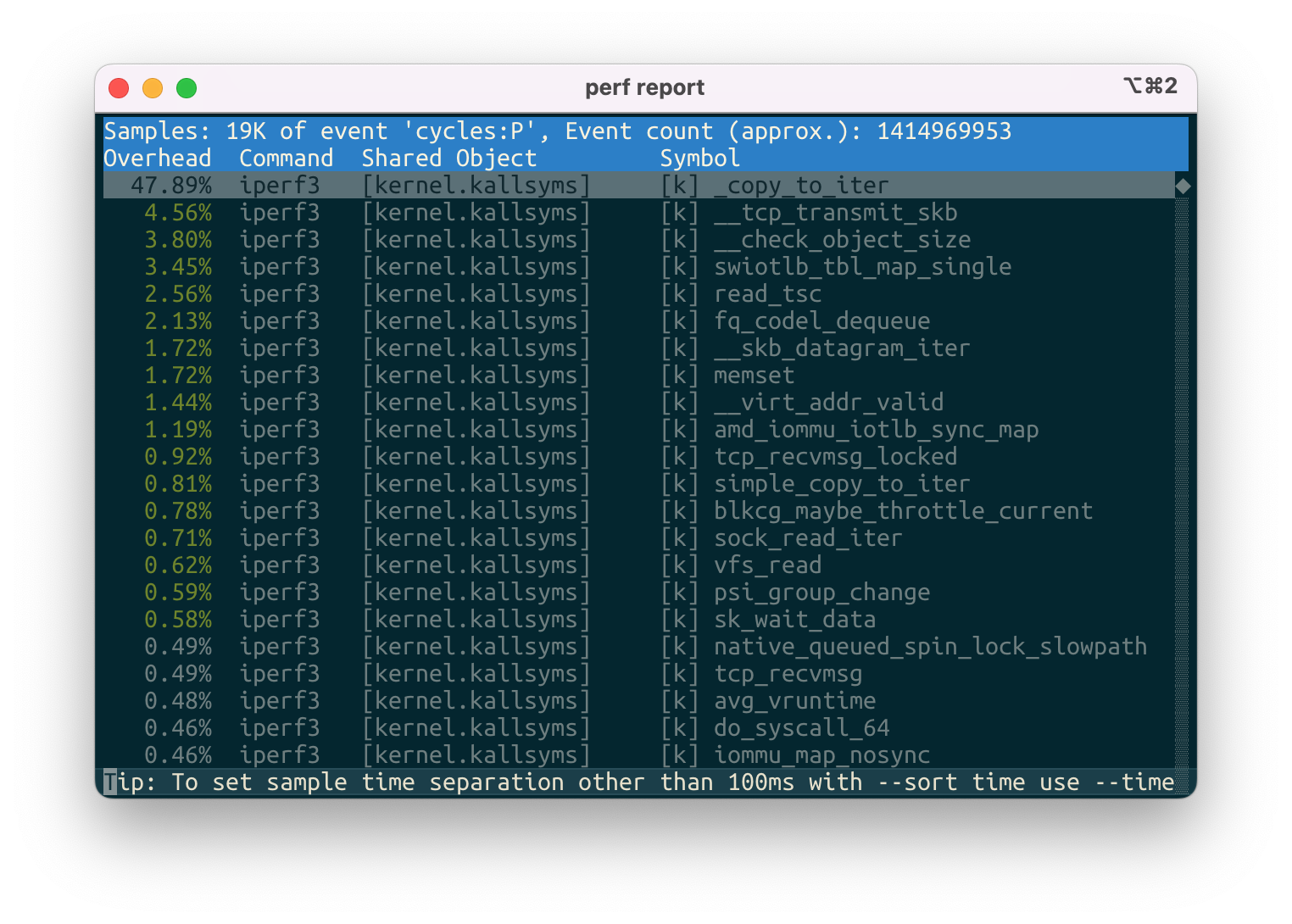
熟悉 IOMMU 的朋友这里应该很容易发现一个异常,那就是出现了 swiotlb 。
为了让更多的读者理解,这里补充一个小知识,在没有 IOMMU 之前,所有的 DMA 外设都可以访问并修改整个物理内存地址空间,对于 Thunderbolt 来说这是个相当危险的事情,意味着通过 Type-C 接口连接一个外设即可 dump 整个物理内存,这样就毫无隐私可言了。在有了 IOMMU 后,通常每个 PCIe Port 会划分为一个单独的 IOMMU Group ,在这个 Group 内的 DMA 访问都通过 IO 页表进行映射并控制读写权限,只有允许外设访问的地址才会在 IO 页表中创建映射,由此外设只能访问其所被操作系统允许访问的物理内存地址空间,并通过虚拟地址的方式外设既不知道真实的物理地址,也不需要保证物理地址的连续。
而 swiotlb 则是一个很特殊的 DMA Buffer,在没有 IOMMU 的时代最初用于解决外设无法访问完整的物理地址空间的情况(例如外设的 DMA 只能访问 32bit 寻址范围内的地址),而如果外设太多的情况下低 32位 的空间可能不够如此多的外设分配。由于 Linux 中大多数的驱动的单个 DMA 地址段都是单向的,即要么是 Device 写 Host 读,要么是 Host 读 Device 写,因此 Linux 可以将这些单向的 DMA 分配到一个 bounce buffer 中,在使用时再进行拷贝即可。而在有了 IOMMU 的时代,它的出现通常用于解决非对齐的 DMA 映射问题。例如我们的 IOMMU 最小映射的粒度是 4KB,但是驱动在调用 dma_map_single 这样的内核函数时,开始地址和结束地址不一定对齐到了页面,此时就会存在外设应该仅能访问页面内的一部分地址段的问题。为此,Linux 在这种情况下继续提供了 swiotlb 作为 work around,前后进行一次拷贝,以实现这段映射空间内不泄漏外设不应该访问的数据。
到此,我们已经发现了驱动可能存在的性能问题,随后,我进行了一个小测试,如果我们完全不管 IO 安全,也就是在 Linux 的启动参数设置 iommu=off ,性能会如何?
我重启了机器测试了一下,结果直接打满 10Gbps:
➜ ~ iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R
Connecting to host fe80::3a63:bbff:fe2e:1a68%enp99s0, port 5201
Reverse mode, remote host fe80::3a63:bbff:fe2e:1a68%enp99s0 is sending
[ 5] local fe80::265e:beff:fe6a:4da1 port 36924 connected to fe80::3a63:bbff:fe2e:1a68 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 1.08 GBytes 9.27 Gbits/sec
[ 5] 1.00-2.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 2.00-3.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 3.00-4.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 4.00-5.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 5.00-6.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 6.00-7.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 7.00-8.00 sec 1.08 GBytes 9.27 Gbits/sec
[ 5] 8.00-9.00 sec 1.08 GBytes 9.25 Gbits/sec
[ 5] 9.00-10.00 sec 1.08 GBytes 9.25 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 10.8 GBytes 9.28 Gbits/sec 29 sender
[ 5] 0.00-10.00 sec 10.8 GBytes 9.27 Gbits/sec receiver
iperf Done.由此,我们已经将性能问题的范围 reduce 到 IOMMU 相关了。但是作为一个有安全素养的人,即使我们我们不连接奇怪的外设,但怎么能相信外设不会有 vulnerability,怎么能关着 IOMMU 直接用呢?
顺藤摸瓜,我开始思考为什么会存在 swiotlb,我开始观测网卡驱动中的 dma_map* 有关函数:
➜ atlantic git:(aqc_fix) pwd
/home/cyy/linux/drivers/net/ethernet/aquantia/atlantic
➜ atlantic git:(aqc_fix) grep -r "dma_map"
atlantic.mod.c: { 0x3d77a902, "dma_map_page_attrs" },
aq_ring.c: daddr = dma_map_page(dev, page, 0, PAGE_SIZE << order,
aq_ring.c: if (unlikely(dma_mapping_error(dev, daddr)))
aq_nic.c: dx_buff->pa = dma_map_single(dev, xdpf->data, dx_buff->len,
aq_nic.c: if (unlikely(dma_mapping_error(dev, dx_buff->pa)))
aq_nic.c: frag_pa = skb_frag_dma_map(dev, frag, buff_offset,
aq_nic.c: if (unlikely(dma_mapping_error(dev, frag_pa)))
aq_nic.c: dx_buff->pa = dma_map_single(dev,
aq_nic.c: if (unlikely(dma_mapping_error(dev, dx_buff->pa))) {
aq_nic.c: frag_pa = skb_frag_dma_map(dev,
aq_nic.c: if (unlikely(dma_mapping_error(dev,这里我们观测到两个 dma_map_single 非常可疑,于是我进行了一番修改,我们把整个页面边界都 map 过去:
diff --git a/drivers/net/ethernet/aquantia/atlantic/aq_nic.c b/drivers/net/ethernet/aquantia/atlantic/aq_nic.c
index b24eaa5283fa..7c6828a0eb2c 100644
--- a/drivers/net/ethernet/aquantia/atlantic/aq_nic.c
+++ b/drivers/net/ethernet/aquantia/atlantic/aq_nic.c
@@ -731,12 +731,16 @@ unsigned int aq_nic_map_skb(struct aq_nic_s *self, struct sk_buff *skb,
}
dx_buff->len = skb_headlen(skb);
+ uintptr_t align_page = ((uintptr_t)skb->data) & PAGE_MASK;
+ uintptr_t align_offset = (uintptr_t)skb->data - align_page;
+ u32 aligned_len = (align_offset + dx_buff->len + PAGE_SIZE - 1U) &
+ PAGE_MASK;
dx_buff->pa = dma_map_single(dev,
- skb->data,
- dx_buff->len,
- DMA_TO_DEVICE);
+ (void*)align_page,
+ aligned_len,
+ DMA_TO_DEVICE) + align_offset;
- if (unlikely(dma_mapping_error(dev, dx_buff->pa))) {
+ if (unlikely(dma_mapping_error(dev, dx_buff->pa - align_offset))) {
ret = 0;
goto exit;
}刚好 liunx-perf 也有 swiotlb 的 event,那我们看看计数器会如何变化吧:
修改前:
➜ linux git:(master) ✗ sudo perf stat -e swiotlb:swiotlb_bounced iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R
Connecting to host fe80::3a63:bbff:fe2e:1a68%enp99s0, port 5201
Reverse mode, remote host fe80::3a63:bbff:fe2e:1a68%enp99s0 is sending
[ 5] local fe80::265e:beff:fe6a:4da1 port 57850 connected to fe80::3a63:bbff:fe2e:1a68 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 268 MBytes 2.24 Gbits/sec
[ 5] 1.00-2.00 sec 266 MBytes 2.24 Gbits/sec
[ 5] 2.00-3.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 3.00-4.00 sec 267 MBytes 2.24 Gbits/sec
[ 5] 4.00-5.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 5.00-6.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 6.00-7.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 7.00-8.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 8.00-9.00 sec 266 MBytes 2.23 Gbits/sec
[ 5] 9.00-10.00 sec 266 MBytes 2.24 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 2.61 GBytes 2.24 Gbits/sec 2 sender
[ 5] 0.00-10.00 sec 2.60 GBytes 2.23 Gbits/sec receiver
iperf Done.
Performance counter stats for 'iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R':
53,183 swiotlb:swiotlb_bounced
10.008265531 seconds time elapsed
0.025647000 seconds user
0.370087000 seconds sys修改后:
➜ linux git:(aqc_swiotlb_fix) ✗ sudo perf stat -e swiotlb:swiotlb_bounced iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R
Connecting to host fe80::3a63:bbff:fe2e:1a68%enp99s0, port 5201
Reverse mode, remote host fe80::3a63:bbff:fe2e:1a68%enp99s0 is sending
[ 5] local fe80::265e:beff:fe6a:4da1 port 43772 connected to fe80::3a63:bbff:fe2e:1a68 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 269 MBytes 2.25 Gbits/sec
[ 5] 1.00-2.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 2.00-3.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 3.00-4.00 sec 269 MBytes 2.25 Gbits/sec
[ 5] 4.00-5.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 5.00-6.00 sec 269 MBytes 2.25 Gbits/sec
[ 5] 6.00-7.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 7.00-8.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 8.00-9.00 sec 268 MBytes 2.25 Gbits/sec
[ 5] 9.00-10.00 sec 268 MBytes 2.25 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 2.62 GBytes 2.25 Gbits/sec 3 sender
[ 5] 0.00-10.00 sec 2.62 GBytes 2.25 Gbits/sec receiver
iperf Done.
Performance counter stats for 'iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R':
8 swiotlb:swiotlb_bounced
10.005899095 seconds time elapsed
0.004480000 seconds user
0.376320000 seconds sys可以看到,虽然 swiotlb_bounced 事件减少到几乎可以忽略不计了,但是性能还是这个鬼样子。
于是我继续阅读驱动的代码和一些参数的文档,无意间让我发现了一个这样的描述:
# Documentation/networking/device_drivers/ethernet/aquantia/atlantic.rst
For some fine tuning and performance optimizations,
some parameters can be changed in the {source_dir}/aq_cfg.h file.
AQ_CFG_RX_PAGEORDER
-------------------
Default value: 0
RX page order override. That's a power of 2 number of RX pages allocated for
each descriptor. Received descriptor size is still limited by
AQ_CFG_RX_FRAME_MAX.
Increasing pageorder makes page reuse better (actual on iommu enabled systems).我们继续观测驱动中接收 eth frame 的代码:
➜ linux git:(aqc_swiotlb_fix) ✗ batcat -r 84:110 drivers/net/ethernet/aquantia/atlantic/aq_ring.c
───────┬──────────────────────────────────────────────────────────────────────────────────────────
│ File: drivers/net/ethernet/aquantia/atlantic/aq_ring.c
───────┼──────────────────────────────────────────────────────────────────────────────────────────
84 │ static int aq_get_rxpages(struct aq_ring_s *self, struct aq_ring_buff_s *rxbuf)
85 │ {
86 │ unsigned int order = self->page_order;
87 │ u16 page_offset = self->page_offset;
88 │ u16 frame_max = self->frame_max;
89 │ u16 tail_size = self->tail_size;
90 │ int ret;
91 │
92 │ if (rxbuf->rxdata.page) {
93 │ /* One means ring is the only user and can reuse */
94 │ if (page_ref_count(rxbuf->rxdata.page) > 1) {
95 │ /* Try reuse buffer */
96 │ rxbuf->rxdata.pg_off += frame_max + page_offset +
97 │ tail_size;
98 │ if (rxbuf->rxdata.pg_off + frame_max + tail_size <=
99 │ (PAGE_SIZE << order)) {
100 │ u64_stats_update_begin(&self->stats.rx.syncp);
101 │ self->stats.rx.pg_flips++;
102 │ u64_stats_update_end(&self->stats.rx.syncp);
103 │
104 │ } else {
105 │ /* Buffer exhausted. We have other users and
106 │ * should release this page and realloc
107 │ */
108 │ aq_free_rxpage(&rxbuf->rxdata,
109 │ aq_nic_get_dev(self->aq_nic));
110 │ u64_stats_update_begin(&self->stats.rx.syncp);
───────┴──────────────────────────────────────────────────────────────────────────────────────────
➜ linux git:(aqc_swiotlb_fix) ✗好家伙,原来这个只是下界呀,明明更大的 rx page order 也就可以存储更多的 rx frame 而不需要频繁修改 IOMMU 的映射。
而让我更加意想不到的是,原来网卡驱动可以如此草台班子,一个 descriptor 只开一个页面,MTU 1500 时只能放 2 个 eth frame,超过了就要进行 Overhead 非常之大的 IOMMU 重映射操作。
于是,我尝试把 AQ_CFG_RX_PAGEORDER 改成了 3,也就是原来的8倍大小的 buffer,并且 revert 了对 swiotlb 的修改,结果:
➜ ~ iperf3 -c fe80::3a63:bbff:fe2e:1a68%enp99s0 -R
Connecting to host fe80::3a63:bbff:fe2e:1a68%enp99s0, port 5201
Reverse mode, remote host fe80::3a63:bbff:fe2e:1a68%enp99s0 is sending
[ 5] local fe80::265e:beff:fe6a:4da1 port 36924 connected to fe80::3a63:bbff:fe2e:1a68 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.00 sec 1.08 GBytes 9.27 Gbits/sec
[ 5] 1.00-2.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 2.00-3.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 3.00-4.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 4.00-5.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 5.00-6.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 6.00-7.00 sec 1.08 GBytes 9.28 Gbits/sec
[ 5] 7.00-8.00 sec 1.08 GBytes 9.27 Gbits/sec
[ 5] 8.00-9.00 sec 1.08 GBytes 9.25 Gbits/sec
[ 5] 9.00-10.00 sec 1.08 GBytes 9.25 Gbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 10.8 GBytes 9.28 Gbits/sec 29 sender
[ 5] 0.00-10.00 sec 10.8 GBytes 9.27 Gbits/sec receiver
iperf Done.轻松跑满 10Gbps !
后续
给 Linux Kernel 交了个 Patch ,让 AQ_CFG_RX_PAGEORDER 可以被直接配置:https://lore.kernel.org/lkml/tencent_E71C2F71D9631843941A5DF87204D1B5B509@qq.com/
看大佬的博客意识到自己的基础知识薄弱🤔
你能想象国内TPlink居然打磨了aqc100的芯片上的型号文字