从与 AMBA AXI 的对比学习 TileLink
Background
最近仔细学习了一下 TileLink 以及 TL-C 的一致性协议,希望写一篇文章给 有AMBA AXI基础 的读者提供一篇 TileLink 快速入门的介绍。
本文参考的 TileLink Spec 基于https://starfivetech.com/uploads/tilelink_spec_1.8.1.pdf
Variant
| Protocol | Narrow Read / Write | Burst | Atomic Op | Cache Coherency |
|---|---|---|---|---|
| AXI4-Lite | ||||
| TL-UL | Y | |||
| AXI4 | Y | Y | Optional+Probe | |
| TL-UH | Y | Y | Y | |
| AXI4+ACE | Y | Y | Y | Y |
| TL-C | Y | Y | Y | Y |
Channel
AMBA AXI 有5个通道,其中, AR 、R 共2个通道用于读请求和读响应, AW 、 W 、 B 分别用于写地址、写数据,写响应。
TileLink 尽管有 A 、 B 、 C 、 D 、 E 共5个通道,但在 TL-C 之前只使用两个 A 与 D ,在这种情况下通道数的减少应该与 AXI + ACE 对比, ACE 增加了 AC(Snoop Address Channel) 、 CR(Snoop response Channel) 、 CD(Snoop data channel) ,这种情况下,AMBA AXI+ACE需要8个独立的通道。
所以我们对于 Channel 的对比可以总结为以下表格:
| Protocol | Channel |
|---|---|
| AXI | AR, R, AW, W, B |
| AXI+ACE | AR, R, AW, W, B, AC, CR, CD |
| TL-UL / TL-UH | A, D |
| TL-C | A, B, C, D, E |
TL-UL 与 TL-UH
TL-UL 与 TL-UH 区别不大,区别仅在于Burst支持、原子操作支持、Intent支持。
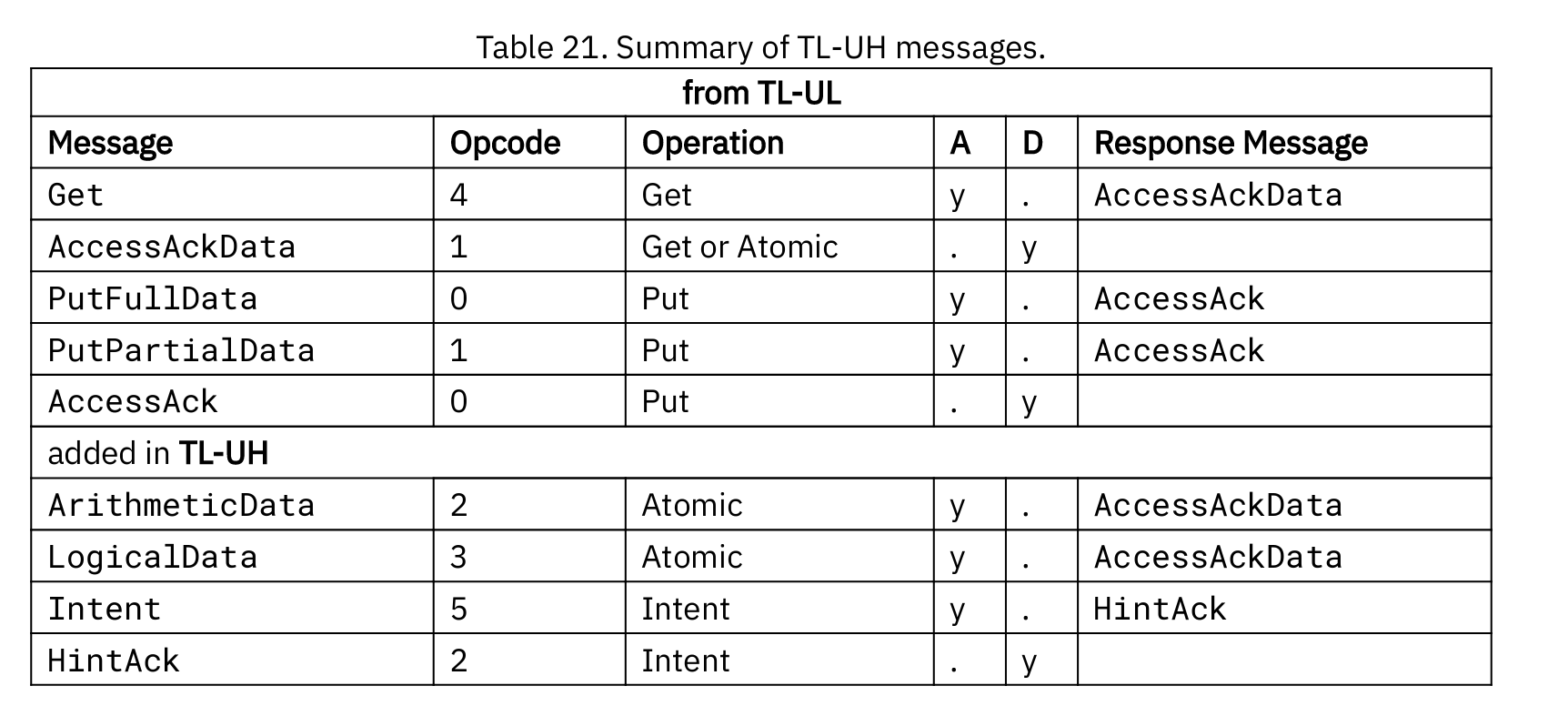
Singal
在我们不考虑 TL-C 一致性之前, TileLink 的 A 通道用途大致相当于集合了 AMBA AXI 的 AW 、 W 、 AR , D 通道大致相当于 AMBA AXI 的 R 和 B 。
TileLink为每个通道增加了Opcode部分,使其可以复用为多个用途。
A
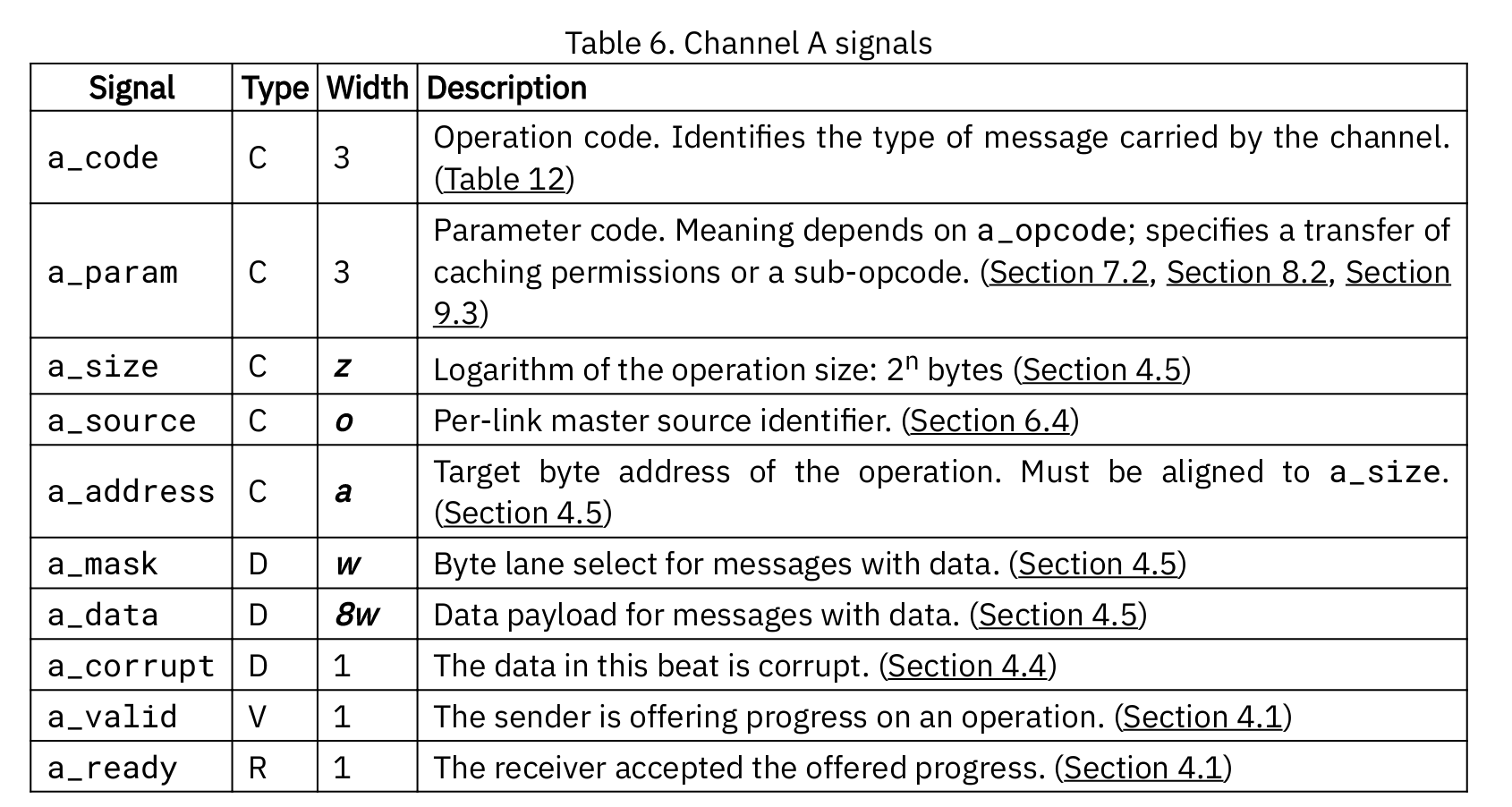
A通道的工作方向是Master->Slave。A通道中的Signal几乎是AMBA AXI中的AR、AW、W所需要功能的并,将地址、请求长度、数据合并在一个通道内。根据Operation Code来选择不同的操作。
D

D通道的工作方向是Slave->Master。D通道的Signal也同样几乎是AMBA AXI中R和B通道的并。
A和D通道中与AMBA AXI的差异
-
等价用途信号名修改
xID -> x_source
xResp -> x_corrupt, x_denied(仅限d通道)
wStrb -> a_mask -
强制对齐
AxLENAxSizeSize相比 AMBA AXI , TileLink 取消了非对齐的突发传输。也就没有 AMBA AXI 中的 len 和 size ,而采用了单一的 size 替代。且该 size 仅能表述为2的整数幂形式。并要求任何请求类型中, address 都应与size 对齐。因此自然,也就没有了 AXI 中的 WARP Burst 以及 Fixed Burst 这两种传输模式,只剩下 INCR 。
评价:个人看法,这个修改避免了总线中一个对性能无关紧要的部分增加复杂度。写过完整 AXI Slave 的读者应该知道 AXI 实现这个是一件多么噩梦的事情,尤其是 narrow burst + 非对齐 + AxLEN 不为1的情况,而 TileLink 不需要处理这样的情况了。
-
没有 last 信号
相比 AMBA AXI , TileLink 对于突发传输的通道取消了 last 信号,但在存在突发传输的 channel 都保留了 size ,因此对于 Shared Access 实现的总线交换节点来说,需要增加一个 Counter 来记录传输是否完成,而不能像 AXI 一样仅需通过 last 信号判断。 -
不支持 Transaction 间 Interleaving
AXI4 中取消了 Write Interleaving ,因此没有了 WID 。而 TileLink 更加直接,连 Read Interleaving 都去除了。我们也从信号不难看出,在去掉了 Last 信号的情况下,如果一个 CrossBar 还要能够支持 Transaction Interleaving ,那么需要实现 $ 2^{Length(source_id)} $ 数量的 Counter 来追踪每个 Transaction 是否结束,这对于 CrossBar 是一个很大的开销。
Transaction
Retractable
在 AMBA AXI 中,一个 Transaction 一旦在一个 Channel 上得到了 Valid 信号即不可撤销,必须一直升高直到等来 Ready 。而在 TileLink 上,撤销的行为是允许的,只要没有出现 valid & ready 都不算已经发出。
Source ID Reuse
与 AMBA AXI 一样, TileLink 支持通过不同的 Source ID 来实现乱序请求。但在相同 Source ID 的行为上则与 AMBA AXI 不同。
在 AMBA AXI 中,允许在 AR 以及 AW / W 通道上多次复用相同的 AxID ,这样我们可以在 R / B 通道上顺序得到先前已经发送的请求。
但在 TileLink 上,对于 A 与 D 通道,必须在 A 通道以某个 Source ID 发出的请求得到 D 通道上的响应后,才可继续复用相同的 Source ID。
Atomic Operation
在同是没有缓存一致性的 AXI4 中,原子操作通过 Slave 提供锁 + 监听修改的方式完成。原子操作使用ARLOCK 与 AWLOCK 信号,Master 可以通过 Slave 检测已经被 LOCK 的读在写时是否被其他 Master 修改,如果被修改则不提交写请求,并在 BRESP 返回 OK 而非 EXOK ,这与 ARMv8.0 中仅有的原子操作 LL / SC 对应(与 RISC-V 中的 LR / SC 相同)。若一个SC操作返回到 CPU 检测非 EXOK ,则等同于 SC 失败。 但在 AXI4 中,并不要求所有的 Slave 都支持 Lock 操作,可以在读时使用 ARLOCK 判断是否在 RRESP 返回 EXOK 进行判断。
TileLink 则不然,放弃了不带缓存一致性的总线实现 LR / SC,但加入了对应 RISC-V A Extension 的amoadd, amomin, amomax等操作,通过 ArithmeticData 和 LogicalData 两种 Opcode 实现。


那么问题就来了, RISC-V 除了这些操作外,还有 LR / SC 怎么办呢?答案是做不了。即使在 AXI4 中,这样的 LOCK 实现也只能适用于没有 Cache 的场景实现 LR / SC,有Cache场景依然需要通过缓存一致性实现。
我们还可以思考TL-UH实现这样原子操作有什么好处,我认为在并行Reduce操作中使用总线的amo操作避免CacheLine在多核核间转移是可以减少总线RTT的。ARM的AMBA CHI总线上也同样支持对应的直接原子操作,ARMv8.1新加入的原子操作指令恰好也能利用这个优势。
TL-C
TileLink-C由于和AMBA ACE差距非常大,建议大家直接阅读SPEC原文进行了解。
LockFreedom
这一部分直接照搬原文:
Forward progress in a quiescent TileLink network requires adherence to these rules:
1. The agent graph contains no cycles
2. Agents must eventually present all beats of a received message
3. Unless they have a higher priority message in flight or unanswered
i. Agents must eventually accept a presented beat
ii. Agents must eventually answer a received request message同时Spec也要求了各通道之间的响应顺序:
In TileLink, there is priority ordering of an agent’s links' channels. A message has a priority which corresponds to the channel on which it is sent. On every link, an agent is either the master or the slave. In increasing priority order:
- channel A on links where the agent is the slave/receiver
- channel A on links where the agent is the master/sender
- channel B on links where the agent is the master/receiver
- channel B on links where the agent is the slave/sender
- channel C on links where the agent is the slave/receiver
- channel C on links where the agent is the master/sender
- channel D on links where the agent is the master/receiver
- channel D on links where the agent is the slave/sender
- channel E on links where the agent is the slave/receiver
- channel E on links where the agent is the master/sender
Notice that response messages are always carried by channels with a higher priority than their requests. Also note that agents which need to forward messages always use a channel with higher priority than the channel from which they receive. These two properties make it fairly easy to follow the forward progress rules.