
Can we trust the cpu cycles from LLVM-MCA?
Background
Recently, I’ve been delving into the ARM SVE2 speed-up over pure NEON in common workloads that are compiled using generic compilers. An interesting finding shows SVE2 can help 436.cactusADM in SPECFP 2006 with GCC 14.2 on Cortex-A720 (Cix P1), but can hinder performance on Neoverse V2 (AWS EC2 r8g, AWS Graviton4). I have control of the environment that uses the same static linked binary and run many times. All the results are reproducible. I tried to understand the result using the llvm-mca tool from the latest LLVM master branch, but the results I obtained were contradictory to the actual experiment.
First glance
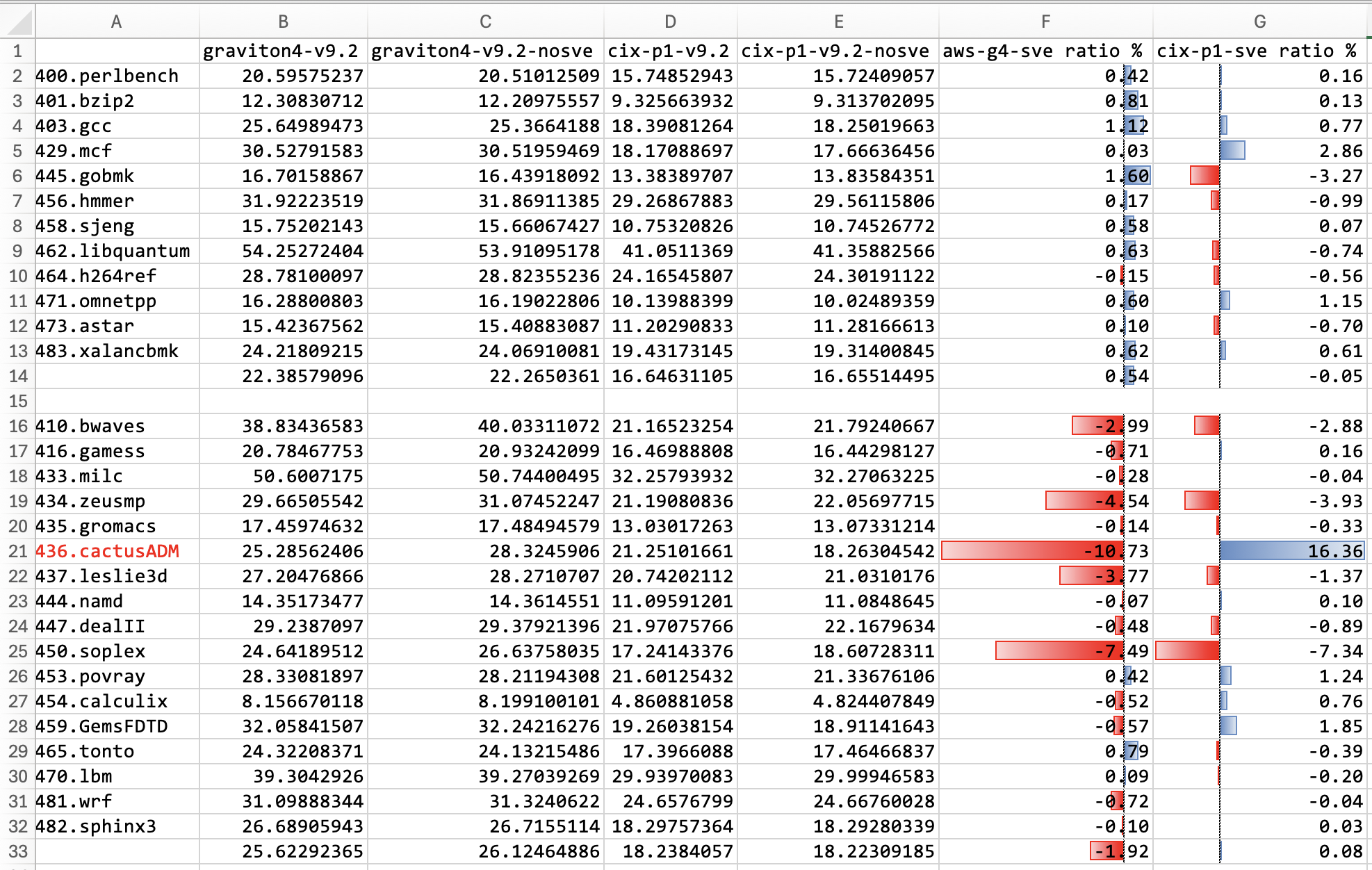
The most strange result is the 436.cactusADM. Surprisingly, it exhibits different performance outcomes when executed on various ARMv9.2-a compatible CPUs. One CPU yields a speed-up, while the other results in a slowdown. Notably, both CPUs have the same SVE vector length of 128 bits.
I tried to understand this result using a CPU performance counter, but I haven’t found any explanations that are comprehensible yet.
Finding the hotspots
Then, I use the perf record command to sample the hotspots in the 436.cactusADM. I discovered that almost all CPU cycles and instructions are consumed by the function bench_staggeredleapfrog2_.

Then, I use my own tool, pybinutils, to create a control flow graph from function bench_staggeredleapfrog2_ with colored hotness (measured by the number of times a basic block is executed) on each node.
./src/draw_cfg.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-nosve-dbg.data -s bench_staggeredleapfrog2_ -c cactusADM_nosve.dot -d cactusADM_nosve_dom.dot -t cactusADM_nosve_scc.dot -m "armv8_pmuv3_0/inst_retired/"
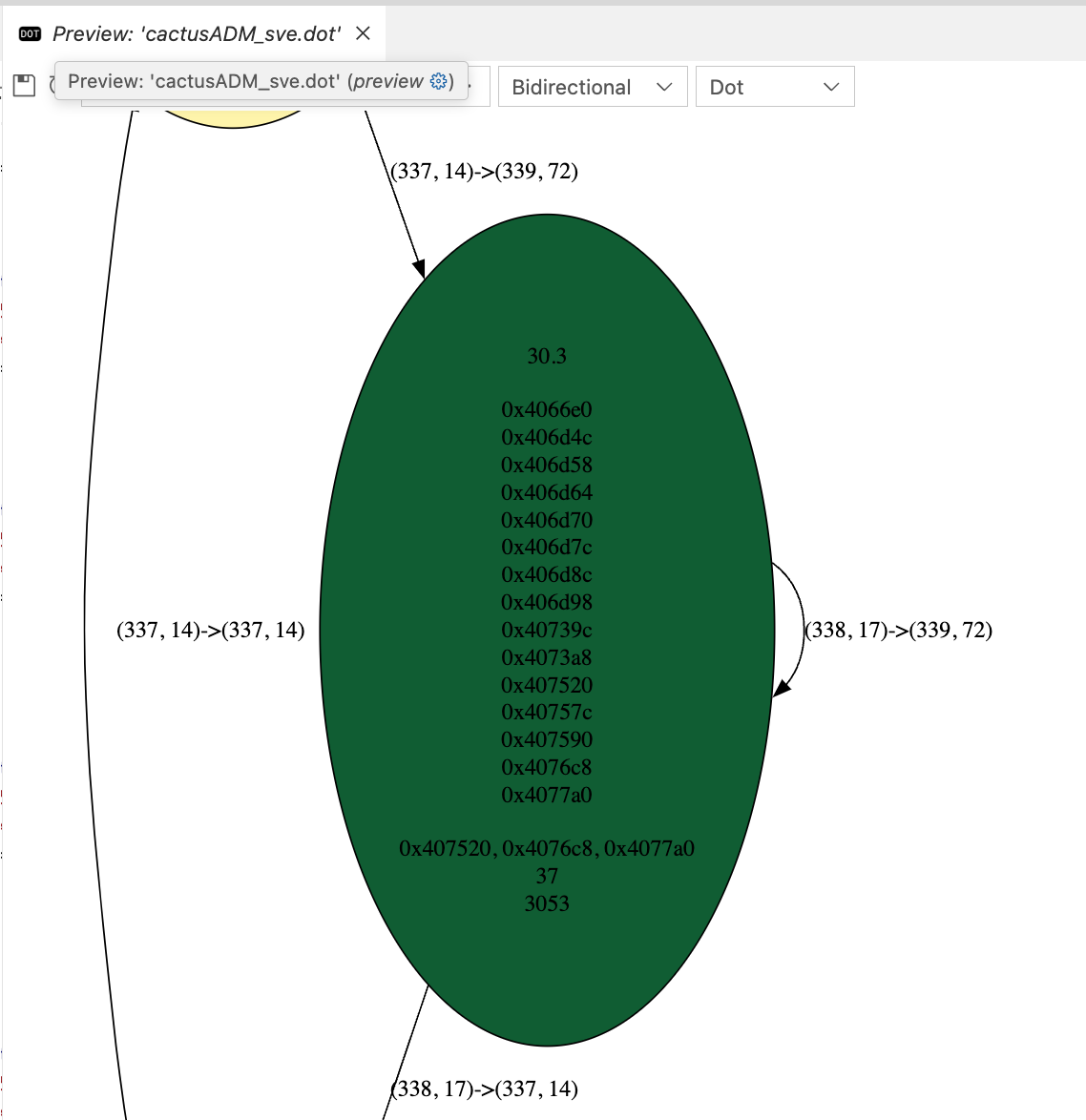
./src/draw_cfg.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-dbg.data -s bench_staggeredleapfrog2_ -c cactusADM_sve.dot -d cactusADM_sve_dom.dot -t cactusADM_sve_scc.dot -m "armv8_pmuv3_0/inst_retired/"This is a CFG compiled from -march=armv9.2-a+nosve+nosve2:

The first line indicates the number of times a basic block is executed in log2. The node is colored based on this metric, with red for the lowest count, yellow for the middle count, and green for the highest count. The second last line shows the number of instructions in a basic block. The middle hex numbers represent the path from the function entry point to the basic block in the dominator tree which created from CFG.
As we can see, the most interesting basic block here is 0x40983c and it is being executed in about 2**(29.6) times. The 0x408da0 and 0x409790 are also most frequently executed, but the instructions in them are relatively small.
And on CFG compiled from -march=armv9.2 (with SVE+SVE2), we got:
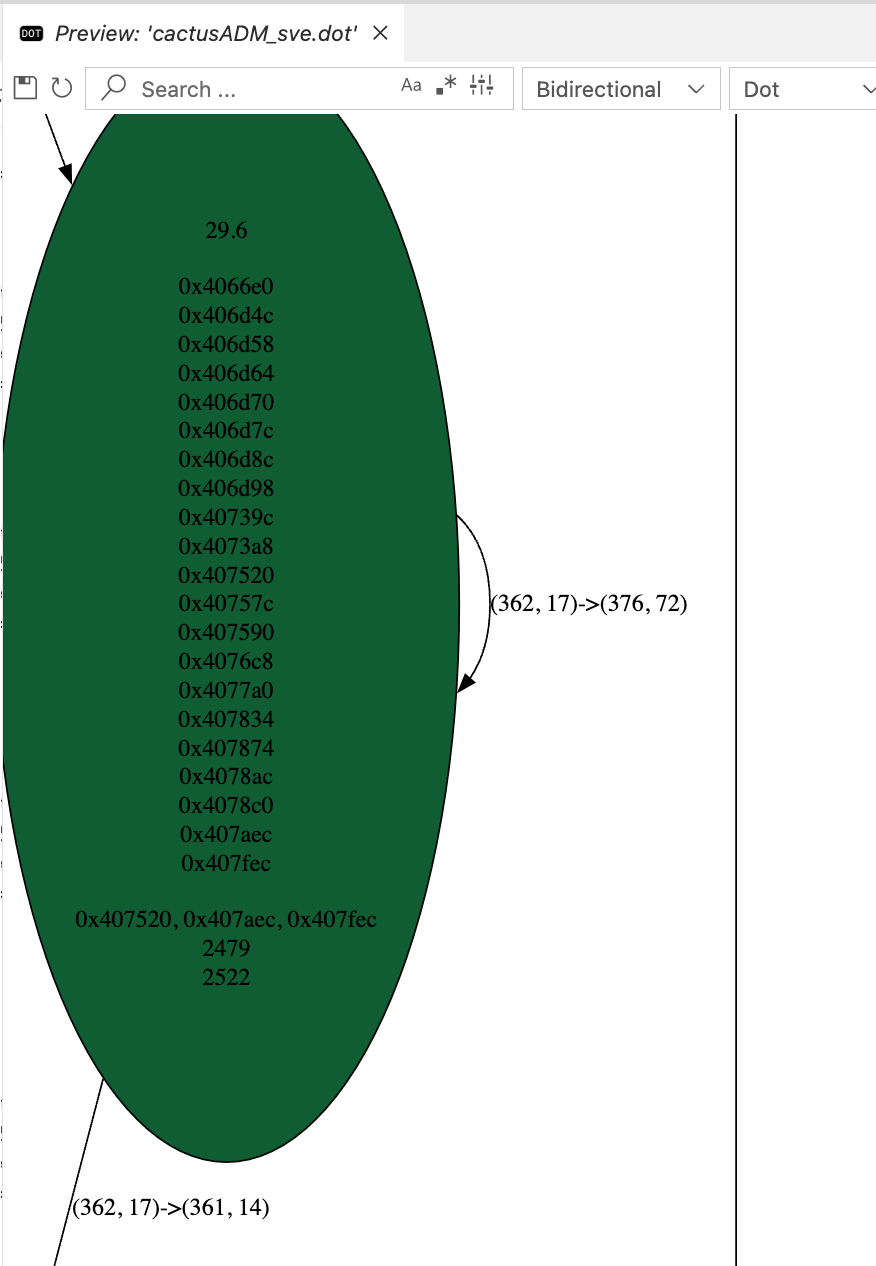
The most interesting blocks here is the basic blocks 0x407fec .
As we can see, the instruction count increased from the no-SVE version. This is consistent with the results of perf stat.
armv9.2-a Version:
2082196671565 armv8_pmuv3_0/inst_retired/
armv9.2-a+nosve+nosve2 Version:
1425848357887 armv8_pmuv3_0/inst_retired/LLVM-MCA
I built LLVM master branch today from commit 7c60725fcf1038f6c84df396496cf52d67ab5b43.
Cortex-A720 result:
➜ pybinutils git:(master) ✗ ./src/dump_basic_block.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-dbg.data -l 0x407fec -m | llvm-mca --march=aarch64 --mcpu=cortex-a720 -skip-unsupported-instructions=parse-failure | head
Iterations: 100
Instructions: 247800
Total Cycles: 55321
Total uOps: 260000
Dispatch Width: 10
uOps Per Cycle: 4.70
IPC: 4.48
Block RThroughput: 498.5
➜ pybinutils git:(master) ✗ ./src/dump_basic_block.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-nosve-dbg.data -l 0x40983c -m | llvm-mca --march=aarch64 --mcpu=cortex-a720 -skip-unsupported-instructions=parse-failure | head
Iterations: 100
Instructions: 163600
Total Cycles: 48930
Total uOps: 207700
Dispatch Width: 10
uOps Per Cycle: 4.24
IPC: 3.34
Block RThroughput: 473.5Neoverse-V2 result:
➜ pybinutils git:(master) ✗ ./src/dump_basic_block.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-dbg.data -l 0x407fec -m | llvm-mca --march=aarch64 --mcpu=neoverse-v2 -skip-unsupported-instructions=parse-failure | head
Iterations: 100
Instructions: 247800
Total Cycles: 31977
Total uOps: 260100
Dispatch Width: 16
uOps Per Cycle: 8.13
IPC: 7.75
Block RThroughput: 219.0
➜ pybinutils git:(master) ✗ ./src/dump_basic_block.py -p /spec_run/CPU2006LiteWrapper/436.cactusADM/perf-aarch64-gcc14.2-12-o3-9.2-nosve-dbg.data -l 0x40983c -m | llvm-mca --march=aarch64 --mcpu=neoverse-v2 -skip-unsupported-instructions=parse-failure | head
Iterations: 100
Instructions: 163600
Total Cycles: 32831
Total uOps: 195700
Dispatch Width: 16
uOps Per Cycle: 5.96
IPC: 4.98
Block RThroughput: 237.7The final result:
| Predicated cycles in 100 iterations | armv9.2-a | armv9.2-a+nosve+nosve2 |
|---|---|---|
| Cortex A720 | 55321 | 48930 |
| Neoverse V2 | 31977 | 32831 |
As we can observe, the performance of nosve varies depending on the processor. It exhibits faster performance on Cortex-A720 but slower performance on Neoverse V2. However, the actual outcome is that nosve performs faster on Neoverse V2 and slower on Cortex-A720.
(To be update….)